

كثير في إطار توحيد دفعة (المشار إليها فيما يلي باسم BN) عمليات في ممارسة معينة هي بسيطة جدا، ليست استثناء في keras، نحن بحاجة فقط لإضافة طبقة BN في النموذج، فهذا يعني تواجه طبقة جعلت التوحيد :
من BatchNormalization keras.layers استيراد كما BN
BN (إبسيلون = 0.001، مركز = صحيح، على نطاق و= صحيح، beta_initializer = "الأصفار"، gamma_initializer = 'منها')
هنا أساسا على المعلمات المتعلقة بعملية التدريب. نحن استخدام الإعدادات الافتراضية المعلمة الرسمية، حيث إبسيلون (

) هو الانحراف المعياري المقدر خلال الضروري إضافة عدد قليل جدا من التباين، لا يمكن أن يعرف لتجنب الانحدار:
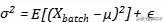
مركز (
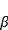
) ومقياس (

) هل تعلم معلمتين يمكن أن يكون تحجيم رد، وضعنا إلى True، وهو ما يعني أننا يمكن أن تتعلم استخدام هذه المعلمتين.

ولا سيما استخدام نحن، يمكن أن يكون انتقائيا الاحتفاظ بها أو رفض بعض. وأخيرا، يمكن للطريقة تعلم تهيئة المعلمات، يمكننا استخدام keras تتم التهيئة.
ناقشنا بشكل رئيسي العديد من القضايا المذكورة في مقال في نظرية:
- بشكل عام، يمكن BN تسريع حقا تدريب ذلك؟
- تنظر فقط ميزة التحجيم، دون النظر التحول متغيرا الداخلي، مع زيادة طبقة BN، فإن التدريب لا يكون الحصول على أفضل وأفضل؟
- إذا كان الوزن تغيرت معطيات المسألة طبقات تنسيق التحديث، ثم حين أن معدل التكيف خوارزمية التعلم وBN ستحقق نتائج أفضل ذلك؟
- ونحن نستخدم دفعة مختلفة في التدريب، وسوف يكون BN نظرة تأثير مثل؟
ما زلنا الاستفادة MNIST مجموعة التدريب البيانات، واستخدام بنية السابق (أو إلى أفضل رؤية تأثير، بحيث يمكننا شبكة أعمق الخاصة)، حفظ نتائج التدريب، لوحظت النتائج المثلى. في بعض الحالات، في مرحلة الاختبار، فإنه يأخذ إخراج كل طبقة، ونتائج الرصد.
نحن أول بيانات الاستيراد، أن تفعل ذلك مع ترميز الساخنة واحد، تطبيع:
استيراد نمباي كما أرستها
من keras.datasets mnist استيراد
من keras.utils to_categorical استيراد
# استيراد البيانات
(X_train، y_train)، (X_test، y_test) = mnist.load_data ()
train_labels = to_categorical (y_train)
test_labels = to_categorical (y_test)
X_train_normal = X_train.reshape (60000،28 * 28)
X_train_normal = X_train_normal.astype ( 'float32') / 255
X_test_normal = X_test.reshape (10000، 28 * 28)
X_test_normal = X_test_normal.astype ( 'float32') / 255
وباستخدام وظيفة السيني كوحدة المخفية لبناء مشترك feedforward الشبكات العصبية:
استيراد نمباي كما أرستها
من keras.datasets mnist استيراد
من keras.models استيراد متسلسل
من keras.layers الكثيفة استيراد
من أبتيميزر استيراد keras
من BatchNormalization keras.layers استيراد كما BN
صفر normal_model (أ):
نموذج = متسلسل ()
model.add (الكثيفة (512، وتفعيل = لذلك، input_shape = (28 * 28،)))
model.add (الكثيفة (256، وتفعيل = أ))
model.add (الكثيفة (128، وتفعيل = أ))
model.add (الكثيفة (64 عاما تفعيل = أ))
model.add (الكثيفة (10، تفعيل = "softmax '))
model.compile (محسن = optimizers.SGD (الزخم = 0.9، نيستيروف = صحيح)، \
فقدان = 'categorical_crossentropy'، \
مقاييس = )
عودة (النموذجي)
إضافة طبقة من BN على أساس النموذج أعلاه، كنموذج جديد:
صفر BN_model (أ):
نموذج = متسلسل ()
model.add (الكثيفة (512، وتفعيل = لذلك، input_shape = (28 * 28،)))
model.add (BN ())
model.add (الكثيفة (256، وتفعيل = أ))
model.add (الكثيفة (128، وتفعيل = أ))
model.add (الكثيفة (64 عاما تفعيل = أ))
model.add (الكثيفة (10، تفعيل = "softmax '))
model.compile (محسن = optimizers.SGD (الزخم = 0.9، نيستيروف = صحيح)، \
فقدان = 'categorical_crossentropy'، \
مقاييس = )
عودة (النموذجي)
نموذجين التدريب إلى 10 العهود، لمراقبة أدائها:
model_1 = normal_model ( 'السيني')
his_1 = model_1.fit (X_train_normal، train_labels، batch_size = 128، validation_data = (X_test_normal، test_labels)، مطول = 1، العهود = 10)
W1 = his_1.history
model_2 = BN_model ( 'السيني')
his_2 = model_2.fit (X_train_normal، train_labels، batch_size = 128، validation_data = (X_test_normal، test_labels)، مطول = 1، العهود = 10)
W2 = his_2.history
matplotlib.pyplot استيراد كما معاهدة قانون البراءات
سيبورن استيراد كما SNS
sns.set (نمط = 'whitegrid')
plt.plot (المدى (10)، W1 ، '-'، التسمية = 'بدون BN')
plt.plot (المدى (10)، W2 ، '-'، التسمية = 'مع BN_1')
plt.title ( 'السيني')
plt.xlabel ( 'العهود')
plt.ylabel ( 'الخسارة')
plt.legend ()

كما هو موضح، يمكنك ان ترى فقط إضافة طبقة من BN، فإن معدل التقارب يصبح أعلى من النموذج دون إضافة الكثير أسرع.
كان لدينا "وحدات مخبأة مشتركة" باستخدام ReLU بدلا من السيني، ومعدل التقارب يصبح أسرع، فإننا سنكون على ما إذا كانت طبقة BN أثبت ReLU حدات مخبأة بشكل جيد لتسريع ذلك مرة أخرى؟ نحن نذهب لاستخدام ReLU، لمراقبة آثاره:

كما هو مبين، كما هو ReLU تخفيفها عن طريق التدرج الخطي نحو الزوال السيني، ولكن BN هو الأفعال تعتمد بإضعاف بين الطبقات، ويجوز للBN زيادة تسريع التقارب على أساس ReLU.
بناء على فهمنا للBN إذا كان حقا لتسريع التقارب عن طريق إضعاف الاعتماد بين طبقات (أو إضعاف shfit متغيرا الداخلي في عملية التمثيل) لنماذج 4-طبقة لدينا، ثم إضافة فقط طبقة من BN، مستقل للأصل مع من الثلاثة الآخرين، ثلاث طبقات من التحسين لا تزال تؤثر على بعضها البعض. ولذلك، فإنه من المتوقع أن، إذا أضفنا طبقة BN، وسرعة التقارب يصبح أسرع.
ممارسة محددة، ننتقل إلى بناء أربعة نماذج، مع كل طبقات مختلفة من BN، وتم تدريبهم على إعطاء الخسارة ومع تغير العهود الخريطة:


كما هو مبين، ونموذج باستخدام وظيفة تفعيل السيني، وتأثير زيادة سرعة التقارب كما يزيد عدد الطبقات، واستخدام نموذج لا يبدو عدد ReLU حساسة من طبقات BN، وذلك باستخدام طبقة من متعدد الطبقات مع عدم وجود فرق كبير، وهذا هو الأرجح لأن الشبكة ليست كافية عميقة، ReLU إضافة طبقة من BN يبدو أن وصلت إلى حدود هذا التحسين نموذج.
سيكون لدينا كود القادم لن يناقش ReLU، لأن النموذج السيني وظيفة تفعيل يبدو أن يكون لها مساحة أكبر ضبط، ونحن أيضا من السهل أن نرى أثره. لتحقيق هذا بسيط نسبيا، فإننا تغيير خوارزمية SGD خوارزمية آدم، من جهة، ويمكننا أن نضيف معدل التعلم التكيفي نموذج تحسين خوارزمية لا تستخدم BN طبقة، من ناحية أخرى، يمكننا أن نضيف نموذج لاستخدام BN طبقة تكييف التعلم الخوارزمية معدل الأمثل لمعرفة ما اذا تسريع التقارب.
ووفقا للمعرفة، BN ومعدل التعلم التكيفي هو تغيير حجم التحديث المعلمة وسائل اثنين، إلى أقصى حد ممكن للحفاظ يتم تحديث المعلمات حجم في أمر من حجم، وليس هناك هرمية.
ممارسة محددة، نحدد اثنين من نماذج جديدة استنادا إلى النموذج أعلاه، هذا واحد لا يستخدم BN، ولكن مع آدم، والآخر باستخدام BN، أيضا استخدام آدم الخوارزمية، ومقارنة مع بداية النموذجين، ضرورة إيلاء الاهتمام ل ونحافظ على آدم وينبغي أن يكون SGD معدل التعلم نفسها، هي 0.01، المعلمات الافتراضية في كل keras يست هي نفسها، تعيين يدويا:

كما هو مبين، وجدنا إضافة آدم نموذج خوارزمية تقوم على استخدام BN، بحيث زيادة تسريع نموذج التقارب، دون استخدام نموذج BN، إضافة آدم الخوارزمية، وجعل BN أيضا تأثير مماثل.
يمكننا أن نرى من الناحية النظرية، ويتم توحيد استنادا إلى الدفعة، الدفعة هي مجموعة فرعية من مجموعة التدريب، وحجمها تؤثر تأثيرا مباشرا على حساب المتوسط والتباين في BN، فمن المرجح كل دفعة ومختلفة الحسابي والتباين.
نفترض أن لتحديد الدفعة، يتم إصلاح المعلمات تطبيع. وخفض التباين (الاختلاف لا BN) بين حجم دفعات الدفعة زيادة، مما يجعل الشبكة لديها تقلبات أكبر. علما، مع ذلك، حتى من دون استخدام BN، حجم دفعة ستظل تؤثر على دفعة كبيرة الانحدار المقدرة التكرار بشكل أسرع، ولكن من السهل الوقوع في الحد الأدنى المحلية، العشوائية دفعة أكثر صغير، ولكن العهود العبور يحتاج الى مزيد من الوقت. وذلك بعد أن تغيير حجم الدفعة، لا يمكن تحديد فعالية تأثير التقارب في النهاية لأن طبقة BN أو لأن تقدير الانحدار.
، أي بإضافة نموذج ونموذج ولكن يمكننا استخدام هذه المشكلة إلى مشكلة أخرى لم يتم إضافة BN BN، ومقارنة أدائها على دفعة مختلفة، وإذا كان على دفعة صغيرة، إضافة نموذج بالمقارنة مع غير BN- إضافة نتائج جيدة نموذج BN لم تنتج، فإنه يظهر، في دفعة صغيرة، BN طبقة لا يعمل.
ووفقا لهذه الفكرة، ونحن نستخدم 4،64،256،1024 أربعة أنواع من حجم الدفعة، على التوالي نموذج BN BN ونموذج لا يضيف التدريب، يمكنك الحصول على:

كما هو مبين، يمكن أن نجد الكثير من المعلومات، لإضافة نموذج BN طبقة (خط متقطع)، عندما يتم الأفضل للBN نموذج (خط الصلبة) لا يتم إضافة حجم دفعة من 64 و 4، وتأثير التقارب والسرعة، ودفعة 4 عندما وأثر هو أيضا أفضل. ولكن في دفعة صغيرة، يجب أن يكون BN من استخدام تأثير يذكر على الأداء، دفعة صغيرة، طبقة BN لكن يجعل الأداء الضعيف.
