1. الذكاء الاصطناعي والثورة التكنولوجية الجديدة
في عام 2017 ، حدث حدث مهم نسبيًا في عالم Go. اجتاحت Master (Alphago) العالم بسلسلة انتصارات مكونة من 60 لعبة ، وهزم العديد من أبطال العالم ، وظهر الذكاء الاصطناعي أمامنا نحن البشر بموقف مهيب. كانت Go تُعرف سابقًا باسم "حصن الحكمة البشرية" ، والآن ، أصبحت هذه القلعة أيضًا شيئًا من الماضي. منذ أن هزمت AlphaGo Li Shishi في مارس 2016 ، دخلت منظمة العفو الدولية مجال رؤية جمهورنا ، وأصبح النقاش حوله أكثر سخونة. تعتقد الصناعة بأكملها عمومًا أنه من المحتمل أن تحدث الثورة التكنولوجية التالية ، وهو أمر متوقع في المستقبل: على مدى السنوات العشر الماضية ، غيّر حياتنا بشكل عميق.

في الواقع ، يمكن للذكاء الاصطناعي القيام بالكثير من الأشياء الممتعة بالإضافة إلى التعرف على الوجوه والأصوات المألوفة لدينا.
على سبيل المثال ، دع الذكاء الاصطناعي يكتب قصائد قديمة بعد تعلم الكثير من القصائد القديمة ، ويمكنه كتابة قصائد قديمة بجودة عالية جدًا.

أو اجمع بين سيارتين بتصميمات مختلفة لتشكيل سيارة جديدة بتصميم جديد.

أيضًا ، كما قد تكون قد رأيت في دائرة الأصدقاء من قبل ، يتم تحويل الصور إلى لوحات من النمط الفني المقابل.

في الوقت الحاضر ، حقق الذكاء الاصطناعي اختراقات شاملة في التقنيات في العديد من المجالات مثل الصورة والكلام. في الوقت نفسه ، ستتبع مشكلة أخرى ، إذا كانت هذه الموجة من الذكاء الاصطناعي ستطلق بالفعل ثورة تكنولوجية جديدة ، فعندئذٍ في المستقبل المنظور ، سيخضع الإنترنت بالكامل لتغييرات هزت الأرض ، مما سيؤثر بشكل عميق على حياتنا. لذا ، بصفتي مهندسًا عاديًا لتطوير الأعمال ، ما هو الموقف والطريقة التي يجب أن أتخذها للتعامل مع تأثير سيل هذه الحقبة؟
قبل الإجابة على هذا السؤال ، دعونا نلقي نظرة على التغييرات في دور المبرمجين الصينيين على مدار الثلاثين عامًا الماضية في الجولة الأخيرة من الثورة التكنولوجية التي قادتها تكنولوجيا معلومات الكمبيوتر:

من الشكل أعلاه ، يمكن تلخيصها بإيجاز: تتطور تكنولوجيا البرمجة باستمرار وتصبح شائعة ، من المهارات التي يتقنها العلماء والخبراء والعلماء في البداية ، إلى التطور التدريجي إلى مهارة عامة. بمعنى آخر ، إذا عاد العديد من كبار المهندسين في شركتنا إلى عام 1980 بفهم وأفكار البرمجة وأجهزة الكمبيوتر الحالية ، فهو بلا شك خبراء الكمبيوتر في تلك الحقبة.
إذا كانت هذه الموجة من الذكاء الاصطناعي ستؤدي حقًا إلى جولة جديدة من الثورة التكنولوجية ، فإننا نعتقد أنها ستتبع مسار تطور مماثل وتتطور تدريجياً وتصبح شائعة. إذا اعتمدنا على هذا الفهم ، ربما ، يمكننا أن نسعى جاهدين لنصبح الجيل الأول من مهندسي الذكاء الاصطناعي من خلال التعلم النشط.
2. تقنية التعلم العميق
تنبع هذه الجولة من الاختراقات التكنولوجية للذكاء الاصطناعي بشكل أساسي من تقنية التعلم العميق ، ولن نكرر تاريخ تطوير الذكاء الاصطناعي والتعلم العميق هنا ، ولكن يمكنك الرجوع إليها بنفسك. لقد أمضيت أكثر من شهر في العمل لفهم تكنولوجيا التعلم العميق وتعلمها. هنا ، أحاول مناقشة مبادئ التعلم العميق بطريقة يسهل على الجميع فهمها من منظور مهندس تطوير الأعمال. على الرغم من تقييد مستواي الفني الشخصي وإتقاني ، إلا أنه قد لا يكون دقيقًا تمامًا.
1. الذكاء البشري والخلايا العصبية
يعتبر الدماغ أهم جزء في ذكاء الإنسان ، وعلى الرغم من أن الدماغ معقد ، إلا أن الوحدات المكونة له بسيطة نسبيًا ، وتتكون القشرة الدماغية والجهاز العصبي بأكمله من خلايا عصبية. من ناحية أخرى ، تتكون الخلية العصبية من التشعبات والمحاور ، والتي تمثل المدخلات والمخرجات ، على التوالي. يُطلق على الهيكل المتشعب المتصل بغشاء الخلية dendrite ، وهو المدخل ، ويسمى "الذيل" الطويل المحور العصبي ، وهو الناتج. تقوم الخلايا العصبية بإخراج إشارات كهربائية وكيميائية ، وأهمها وجود دفعة كهربائية تنتشر على طول سطح غشاء الخلية المحورية. بتجاهل كل التفاصيل ، فإن الخلية العصبية هي جهاز بسيط نسبيًا يجمع ما يكفي من المدخلات لإنتاج مخرجات (إثارة).

يحتوي كل من التشعبات والمحاور على عدد كبير من الفروع ، وعادة ما تتصل نهايات المحاور بتغصنات الخلايا الأخرى في بنية تسمى "المشبك". ينتقل ناتج الخلايا العصبية إلى آلاف الخلايا العصبية في اتجاه مجرى النهر من خلال المشابك العصبية ، ويمكن للخلايا العصبية ضبط قوة ربط المشابك ، وتعزز بعض المشابك العصبية من إثارة الخلايا في اتجاه مجرى النهر ، بينما يثبط البعض الآخر. تحتوي الخلية العصبية على آلاف الخلايا العصبية المنبثقة ، وتجمع مدخلاتها وتنتج مخرجاتها.
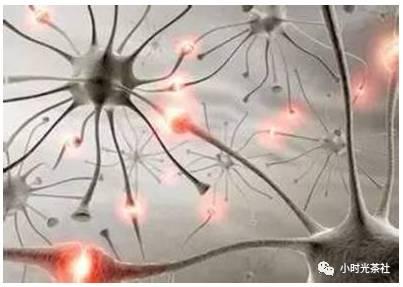
يمتلك دماغ الإنسان 100 مليار خلية عصبية و 1000 تريليون نقطة اشتباك عصبية ، والتي تشكل شبكة عصبية ضخمة في دماغ الإنسان ، والنتيجة النهائية هي ذكاء الإنسان.
2. الخلايا العصبية الاصطناعية والشبكات العصبية
إن بنية الخلية العصبية بسيطة نسبيًا ، لذلك يفكر العلماء ، هل يمكن للذكاء الاصطناعي أن يتعلم منها؟ الطريقة التي تستقبل بها الخلايا العصبية الإثارة وإخراج الاستجابة تشبه إلى حد بعيد المدخلات والمخرجات في الكمبيوتر ، ويبدو أنها مصممة خصيصًا ، ويمكن محاكاتها فقط من خلال وظيفة.

من خلال استعارة آلية الخلايا العصبية والرجوع إليها ، قام العلماء بمحاكاة الخلايا العصبية الاصطناعية والشبكات العصبية الاصطناعية. بالطبع ، من خلال الوصف والمخطط التجريدي أعلاه ، يصعب على الجميع فهم آليتها ومبدأها. لنأخذ "قياس سعر المنزل" كمثال ، دعنا نلقي نظرة:
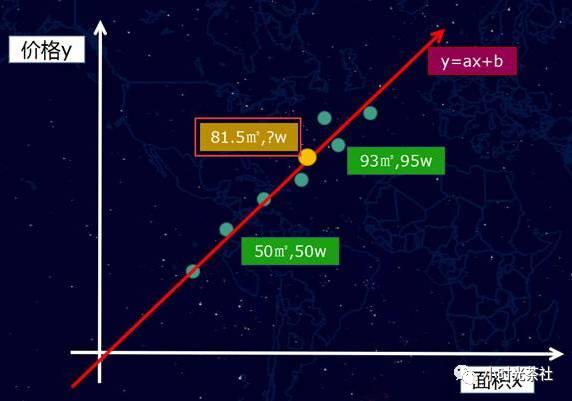
سيتأثر سعر المنزل بالعديد من العوامل ، مثل الموقع والتوجه والعمر والمنطقة وسعر الفائدة البنكية وما إلى ذلك. إذا تم تقسيم هذه العوامل ، فقد يكون هناك العشرات منها. بشكل عام في نماذج التعلم العميق ، تسمى هذه العوامل التي تؤثر على النتائج ميزات. لنفترض أولاً سيناريو متطرف ، على سبيل المثال ، هناك ميزة واحدة فقط تؤثر على السعر ، وهي حجم المنزل. لذلك قمنا بجمع مجموعة من البيانات ذات الصلة ، على سبيل المثال ، سلسلة من بيانات العينة مثل 500000 متر مربع ، 93 مترًا مربعًا ، 950000. إذا تم وضع بيانات العينة هذه في إحداثيات الجانب الآخر ، فسيكون على النحو التالي:

ثم ، كما قلنا من قبل ، نحاول أن نلائم هذا المدخل (المنطقة x) والمخرج (السعر y) مع "دالة" ، باختصار ، نريد "ملاءمة هذه النقاط" من خلال خط أو منحنى معًا ".
بافتراض أن الموقف شديد الخطورة أيضًا ، يمكن فقط تزويد هذه النقاط بـ "خط مستقيم" (الوضع الحقيقي ليس في العادة خطًا مستقيمًا) ، كما هو موضح أدناه:

إذن وظيفتنا هي معادلة أحادية البعد f (x) = ax + b ، بالطبع ، إذا كانت منحنى ، فسنحصل على معادلة متعددة الأبعاد. بعد أن نحصل على وظيفة f (x) = ax + b ، يمكننا بعد ذلك إجراء "تنبؤ" لأسعار المنازل ، على سبيل المثال ، يمكننا حساب حالة مساحة 81.5 مترًا مربعًا لم نشهدها من قبل ، وكم هو هو - هي؟
في هذه الحالة النموذجية الجديدة ، يمكن العثور على النقطة المقابلة (النقطة الصفراء) بخط مستقيم ، كما هو موضح أدناه:
لفهم تقريبي ، ما سبق هو العملية العامة للذكاء الاصطناعي. كل هذا يبدو بسيطًا جدًا؟ بالطبع لا ، لأنه كما ذكرنا سابقًا ، هناك أكثر من ميزة تؤثر على أسعار المساكن ، ولكن العشرات منها ، مما يجعل المشكلة أكثر تعقيدًا.بعد ذلك ، سنستمر في تقديم طريقة التدريب لنموذج التعلم العميق . هذا الجزء معقد نسبيًا ، وأحاول تقديم شرح تقريبي وبسيط من منظور مهندس أعمال.
3. كيفية تدريب نماذج التعلم العميق
عندما يكون هناك عشرات الميزات التي تؤثر على السعر معًا ، فمن الطبيعي أن تكون مشكلة توزيع الوزن متضمنة. على سبيل المثال ، يكون لبعضها وزن إيجابي على سعر المنزل ، مثل الموقع ، والمساحة ، وما إلى ذلك ، وبعضها له وزن سلبي ، مثل عمر المنزل ، وما إلى ذلك.
(1) بدء حساب الوزن
لذا ، فإن الخطوة الأولى في الواقع هي إضافة قيمة وزن لهذه الميزات ، لكن في البداية لا نعرف ما هي قيم الوزن هذه على الإطلاق؟ كيف افعلها؟ بغض النظر عن هذا القدر ، دعنا نخصص لهم قيمة عشوائية أولاً. مع التخصيص العشوائي ، فإن السعر التقديري النهائي للمنزل غير دقيق بالتأكيد. على سبيل المثال ، قد يحسب منزلًا بقيمة 1 مليون إلى 100000.
(2) وظيفة الخسارة
نظرًا لوجود فجوة كبيرة بين تقييم النموذج والتقييم الفعلي ، نحتاج إلى تقديم دور قياس لتقييم درجة "عدم الدقة" ، أي دالة الخسارة ، وهي معيار لقياس الفجوة بين تقدير النموذج القيمة والقيمة الحقيقية ، كلما كانت دالة الخسارة أصغر ، كلما قل إدراك القيمة المقدرة والقيمة الحقيقية للنموذج ، وهدفنا الأساسي هو تقليل دالة الخسارة هذه. دع التقدير النموذجي لميزات المنزل يقترب الآن من تقدير المليون.
(3) تعديل النموذج
من خلال الانحدار المتدرج والانتشار العكسي ، يتم حسابه لضبط معاملات الوزن في اتجاه تقليل وظيفة الخسارة. لإعطاء تشبيه غير مناسب ، نضيف بعض الوزن إلى المنطقة ، ثم نخفض بعض الوزن إلى اتجاه المنزل (طريقة الحساب الفعلية ، وليس تعديل خصائص حالة واحدة) ، ثم تصبح وظيفة الخسارة أصغر.
(4) تكرار التكرار الحلقي
بعد ضبط وزن النموذج ، يمكنك إعادة أخذ دفعة جديدة من بيانات العينة ، وتكرار الخطوات السابقة ، وبعد مئات الآلاف أو أكثر من أوقات التدريب ، تكون القيمة المقدرة للنموذج المقدر النهائي قريبة من القيمة الحقيقية هذا النموذج هو "الوظيفة" التي نريدها.

من أجل تسهيل فهم الجميع وبديهية ، فإن الأمثلة المستخدمة تقريبية نسبيًا ، ويتم وصف عملية التدريب الخاصة بنموذج التعلم العميق ، ويتم حذف العديد من التفاصيل في المنتصف. بعد الحديث عن المبدأ ، دعنا نبدأ الحديث عن كيفية التعلم وبناء العرض التوضيحي.
3. بناء بيئة تعليمية عميقة
قبل شهرين ، كان الذكاء الاصطناعي مجرد فكرة عظيمة بالنسبة لي. ومع ذلك ، بعد أكثر من شهر من الدراسة الجادة في أوقات فراغي ، وجدت أنه لا يزال بإمكاني تعلم شيء ما وتشغيل بعض العروض التوضيحية والتطبيقات.
1. التحضير للدراسة
(1) مراجعة بعض محتويات الرياضيات ، بعض المحتويات مثل رياضيات المدرسة الثانوية ، الاحتمالات ، الجبر الخطي ، إلخ. (استغرق الأمر ما مجموعه 10 ساعات ، واخترت النقاط الرئيسية وقرأتها ، لكن ذلك لم يكن كافيًا. عندما كان بإمكاني فقط أن أجعل نفسي أنظر إلى الصيغة ، لم أكن مرتبكًا جدًا).
(2) تعلم قواعد لغة بايثون الأساسي. (استغرق الأمر حوالي 3 ساعات ، ولم أكتب Python من قبل ، لأن استخدام إطار عمل TensorFlow من Google يعتمد على Python)
(3) إطار عمل TensorFlow للتعلم العميق مفتوح المصدر من Google. (قضى أكثر من 10 ساعات لرؤية)
يمكن للطلاب الذين لديهم أساس جيد في الرياضيات أو الذين لا ينتبهون للمبادئ في مرحلة مبكرة أن يبدأوا في فعل ذلك دون قراءة الجزء المتعلق بالرياضيات ، فالأمر متروك تمامًا للاختيار الشخصي.
2. إطار عمل التعلم العميق مفتوح المصدر TensorFlow من Google
يمكن فهم إطار عمل التعلم العميق على أنه مجموعة من "الوظائف الرياضية" وإطار تنفيذي لتدريب وتعلم الذكاء الاصطناعي. من خلاله ، يمكننا تشغيل نموذج الذكاء الاصطناعي وصيانته بشكل أفضل.
هناك إصدارات مختلفة من أطر التعلم العميق (Caffe ، و Torch ، و Theano ، وما إلى ذلك) ، وليس لدي سوى اتصال بـ TensorFlow من Google ، لذلك فإن المحتوى التالي يعتمد على TensorFlow ، ولن يتم وصف مقدمته التفصيلية هنا. يوصى قم بزيارة الموقع الرسمي مباشرة. من حسن الحظ أن TensorFlow لديه مجتمع صيني لفترة طويلة. على الرغم من أن المحتوى فيه قديم بعض الشيء وهناك بعض المآزق في بيئة البناء ، إلا أنه بالفعل أحد الوثائق الصينية القليلة. دعونا نشاهده ونعتز به.
مجتمع TensorFlow الصيني:
مجتمع TensorFlow باللغة الإنجليزية:
3. بناء بيئة TensorFlow
بناء البيئة نفسه ليس معقدًا ، فهو يحل بشكل أساسي التبعيات ذات الصلة. ومع ذلك ، فإن التبعية الأساسية للمكتبة يمكن أن تسبب العديد من المشاكل ، لذلك يوصى بعملها في خطوة واحدة قدر الإمكان ، والتي ستكون أبسط بكثير.
(1) نظام التشغيل
الآلة التي أستخدمها لبناء البيئة هي آلة على Tencent Cloud ، وبيئة البرنامج هي كما يلي:
نظام التشغيل: CentOS 7.264-bit (GCC 4.8.5)
لأن هذا الإطار يعتمد على python2.7 و glibc 2.17. الإصدار الأقدم من CentOS هو بشكل عام python2.6 والإصدار الأدنى من glibc ، والذي سيؤدي إلى مشكلة تبعية مكتبة متعددة القواعد نسبيًا. علاوة على ذلك ، باعتبارها المكتبة الأساسية لنظام Linux ، فإن glibc أكثر تعقيدًا لترقيتها مباشرةً ، ومن المحتمل أن تتسبب في المزيد من مشاكل البيئة غير الطبيعية.
(2) بيئة البرمجيات
إصدار Python الذي أقوم بتثبيته حاليًا هو python-2.7.5. يوصى بتثبيت البرنامج الأصلي ذي الصلة عن طريق yum install python. بعد ذلك ، قم بتثبيت مدير حزمة المكونات pip في python. بعد تثبيت pip ، يكون تثبيت البرامج الأخرى أمرًا بسيطًا نسبيًا.
على سبيل المثال ، يمكن تثبيت TensorFlow باستخدام الأمر التالي (سيساعد تلقائيًا في حل بعض تبعيات المكتبة):
تثبيت Pip -U tensorflow
ما يحتاج إلى اهتمام خاص هنا هو عدم اتباع تعليمات مجتمع TensorFlow الصيني للتثبيت ، لأنه سيثبت إصدارًا قديمًا جدًا (0.5.0) ، وستواجه مشكلات عند تشغيل العديد من العروض التوضيحية مع هذا الإصدار. في الواقع ، التثبيت الحالي من خلال الأمر المذكور أعلاه هو إصدار tensorflow (1.0.0).
المكونات الرئيسية الأخرى التي يجب تثبيتها في Python (2.7.5):
Tensorflow (0.12.1) ، الإطار الأساسي للتعلم العميق
image (1.5.5) ، المتعلقة بمعالجة الصور ، سيتم استخدام بعض الأمثلة
PIL (1.1.7) ، المتعلقة بمعالجة الصور ، سيتم استخدام بعض الأمثلة
بالإضافة إلى ذلك ، بالطبع ، هناك مكونات أخرى تابعة.يمكنك عرض مكونات Python التي قمنا بتثبيتها من خلال أمر pip list:
-
appdirs (1.4.0)
-
backports.ssl-match-hostname (3.4.0.2)
-
شارديت (2.2.1)
-
configobj (4.7.2)
-
الديكور (3.4.0)
-
جانغو (1.10.4)
-
funcsigs (1.0.2)
-
صورة (1.5.5)
-
iniparse (0.4)
-
المطبخ (1.1.1)
-
لانجتابل (0.0.31)
-
وهمية (2.0.0)
-
numpy (1.12.0)
-
التعبئة والتغليف (16.8)
-
pbr (1.10.0)
-
أداء (0.1)
-
PIL (1.1.7)
-
وسادة (3.4.2)
-
نقطة (9.0.1)
-
بروتوبوف (3.2.0)
-
بيكورل (7.19.0)
-
pygobject (3.14.0)
-
pygpgme (0.3)
-
بيليبلزما (0.5.3)
-
pyparsing (2.1.10)
-
بيثون أوغياس (0.5.0)
-
python-dmidecode (3.10.13)
-
بيودف (0.15)
-
بيكساتر (0.5.1)
-
أدوات الإعداد (34.2.0)
-
ستة (1.10.0)
-
انزلاق (0.4.0)
-
انزلاق dbus (0.4.0)
-
Tensorflow (1.0.0)
-
urlgrabber (3.10)
-
عجلة (0.29.0)
-
yum-langpacks (0.4.2)
-
محلل البيانات الوصفية yum (1.1.4)
يمكن أن يؤدي بناء النظام وفقًا لما سبق إلى تجنب العديد من المشكلات البيئية.
في عملية إعداد البيئة ، واجهت العديد من المشاكل. على سبيل المثال: حدث خطأ عند تشغيل المثال الرسمي ، AttributeError: الكائن 'module' ليس له سمة 'gfile' ، لأن الإصدار المثبت من TensorFlow أقدم ويفتقر إلى وحدة gfile. وهناك كل الأنواع. (لا تسألني كيف أعرف ، سأبكي كثيرًا ~)
إرشادات التثبيت الأكثر تفصيلاً:
(3) تشغيل اختبار بيئة TensorFlow
لاختبار ما إذا كان التثبيت ناجحًا ، يمكنك استخدام مثال قصير مقدم من المسؤول ، حيث يولد العرض التوضيحي بعض البيانات ثلاثية الأبعاد ، ثم يستخدم مستوى لملاءمتها (الوظيفة المستخدمة في مثال الموقع الرسمي لتهيئة المتغيرات هي initialize_all_variables ، وهو موجود بالفعل في الإصدار الجديد. مهمل):
#! / usr / bin / python
# الترميز = utf-8
استيراد tensorflow مثل tf
استيراد numpy كـ np
# استخدم NumPy لإنشاء بيانات زائفة ، إجمالي 100 نقطة.
x_data = np.float32 (np.random.rand (2 ، 100)) # إدخال عشوائي
y_data = np.dot (، x_data) + 0.300
# بناء نموذج خطي
#
ب = tf. متغير (tf.zeros ())
W = tf متغير (tf.random_uniform (، -1.0 ، 1.0))
y = tf.matmul (W ، x_data) + ب
# تقليل التباين
الخسارة = tf.reduce_mean (tf.square (y - y_data))
محسن = tf.train.GradientDescentOptimizer (0.5)
القطار = Optizer.minimize (الخسارة)
# تهيئة المتغيرات ، فقد تم إهمال الوظيفة القديمة (initialize_all_variables) واستبدالها بوظيفة جديدة
init = tf.global_variables_initializer
# بدء الرسم البياني (رسم بياني)
sess = tf.Session
sess.run (الحرف الأول)
# تناسب الطائرة
للخطوة في xrange (0 ، 201):
sess.run (قطار)
إذا كانت الخطوة 20 == 0:
خطوة الطباعة ، sess.run (W) ، sess.run (ب)
# احصل على أفضل نتيجة ملائمة W:، b:
نتيجة الجري مشابهة لما يلي:

بعد 200 مرة من التدريب ، تقترب معلمات النموذج تدريجيًا من أفضل نتيجة ملائمة (W: ، b:). بالإضافة إلى ذلك ، يمكننا أيضًا معرفة وضع التشغيل الأساسي لتدريب عينة الإطار من "أسلوب" الكود. على الرغم من أن البرنامج التعليمي الرسمي سيتضمن المزيد والمزيد من الأمثلة المعقدة في المستقبل ، إلا أنه بشكل عام نمط مماثل.
تقسيم الخطوة:
-
تحضير البيانات: الحصول على بيانات نموذجية معنونة (تسمى بيانات التدريب المسمى التعلم الخاضع للإشراف) ؛
-
قم بإعداد النموذج: أولاً قم ببناء نموذج التدريب الذي يجب استخدامه ، وهناك بالفعل عدد لا بأس به من طرق التعلم الآلي للاختيار من بينها ، وبعبارة أخرى ، إنها مجموعة من الوظائف الرياضية ؛
-
وظيفة الخسارة وطريقة التحسين: قياس الفجوة بين نتيجة حساب النموذج وقيمة التسمية الحقيقية ؛
-
عملية تدريب حقيقية: يسمح النموذج الذي تم إنشاؤه قبل التدريب للبرنامج بالحصول على "المعلمات" النهائية للنتيجة التي نحتاجها من خلال التدريب والتعلم الدائري ؛
-
نتائج التحقق: استخدم بيانات مجموعة الاختبار التي لم يتم تدريب النموذج عليها للتحقق من دقة النموذج.
من بينها ، من أجل تحقيق حساب رياضي فعال يعتمد على بايثون ، يستخدم TensorFlow عادةً بعض مكتبات الوظائف الأساسية ، مثل Numpy (يتم تنفيذه بلغة خارجية منخفضة المستوى) ، ولكن هناك أيضًا عبء في التبديل مرة أخرى إلى Python من الحساب الخارجي ، خاصة في عدة آلاف ومئات الآلاف من الدورات التدريبية. لذلك ، لا يُجري Tensorflow عملية حسابية لوظيفة واحدة بشكل منفصل ، ولكنه يصف أولاً سلسلة من عمليات الحوسبة التفاعلية مع الرسوم البيانية ، ثم يرسلها جميعًا إلى العملية الخارجية في وقت واحد (تُستخدم تطبيقات مماثلة أيضًا في مكتبات تعلم الآلة الأخرى) . لذلك ، في مخطط التدفق أعلاه ، يحدد الجزء الأزرق فقط "عملية عملية الحساب" ، والجزء الأخضر هو بيانات الإرسال الحقيقية إلى المكتبة الأساسية للتشغيل الفعلي ، وينفذ كل تدريب بشكل عام مجموعة من البيانات على دفعات.
رابعًا ، العرض التوضيحي الكلاسيكي للدخول: التعرف على الأرقام المكتوبة بخط اليد (MNIST)
أول البرمجة العادية هو برنامج "Hello world" ، وأساس التعلم العميق هو MNIST ، وهو برنامج يتعرف على الأرقام المكتوبة بخط اليد في صورة 28 28 بكسل.
بيانات MNIST والموقع الرسمي:
يتضمن محتوى التعلم العميق المزيد من المبادئ الرياضية وراءه. كمبتدئ ، مقيدًا بالرياضيات الشخصية والمستوى التقني ، قد لا يكون كافياً لوصف المبادئ الرياضية ذات الصلة بدقة. لذلك ، ستولي هذه المقالة مزيدًا من الاهتمام لـ "التطبيق المستوى "لا يوسع المبادئ الرياضية الكامنة وراءه ، شكرًا لتفهمك.
1. تحميل البيانات
الخطوة الأولى في تنفيذ البرنامج هي بالطبع تحميل البيانات ، وفقًا لمجموعة البيانات التي حصلنا عليها من قبل ، فهي تتضمن بشكل أساسي جزأين: 60000 مجموعة بيانات تدريب (mnist.train) ومجموعة بيانات اختبار 10000 (mnist.test). كل سطر فيه عبارة عن مصفوفة 28 * 28 = 784. جوهر المصفوفة هو تحويل الصورة 28 * 28 بكسل إلى مصفوفة البكسل المقابلة.
على سبيل المثال ، يتم التعبير عن المصفوفة المقابلة المحولة من صورة الكلمة المكتوبة بخط اليد 1 على النحو التالي:

لقد سمعنا كثيرًا من قبل أن التعلم العميق في الصور يتطلب قدرًا كبيرًا من قوة الحوسبة ، بل ويتطلب أيضًا استخدام وحدات معالجة رسومات احترافية باهظة الثمن (Nvidia GPUs). يمكننا بالفعل الحصول على بعض الإجابات من حالات التحويل المذكورة أعلاه. تحتوي الصورة التي تبلغ دقتها 784 بكسل على 784 ميزة لنموذج التعلم ، وغالبًا ما تكون صورنا وصورنا الفعلية بمئات الآلاف أو الملايين ، لذا فإن الميزات الأساسية المقابلة هي أيضًا بهذا الترتيب من حيث الحجم ، استنادًا إلى مصفوفة بهذا الترتيب من حيث الحجم من المستحيل حقًا إجراء عمليات على نطاق واسع دون دعم قوة الحوسبة القوية. بالطبع ، لا يزال من الممكن تشغيل عرض MNIST للمبتدئين بسرعة نسبيًا.
رمز المفتاح في العرض التوضيحي (قراءة البيانات وتحميلها في كائن مصفوفة لاستخدامها لاحقًا):
2. بناء النموذج
تمثل كل صورة في MNIST رقمًا ، من 0 إلى 9. ما يتوقعه النموذج في النهاية هو: عند إعطاء صورة ، احصل على احتمال تمثيل كل رقم. على سبيل المثال ، قد يستنتج النموذج أن صورة الرقم 9 لديها فرصة 80 لتمثيل الرقم 9 لكن فرصة 5 أن تكون 8 (لأن كلا 8 و 9 لهما دوائر صغيرة في النصف العلوي) ، و ثم أعطها تمثيلاً للقيمة A الأخرى مع احتمال أصغر لرقم.

يستخدم المثال التمهيدي لـ MNIST انحدار softmax. يمكن استخدام نموذج softmax لتعيين الاحتمالات لكائنات مختلفة.
للحصول على دليل على أن صورة معينة تنتمي إلى فئة أرقام معينة ، نقوم بإجراء مجموع مرجح لميزات الصورة 784 (قيمة كل بكسل في شبكة). إذا كانت الميزة (قيمة البكسل) لديها دليل قوي على أن الصورة لا تنتمي إلى هذه الفئة ، فإن قيمة الوزن المقابلة تكون سالبة ، على العكس من ذلك إذا كانت الميزة (قيمة البكسل) لديها دليل مؤات على أن الصورة تنتمي إلى هذه الفئة ، إذن قيمة الوزن موجبة. على غرار مثال تقدير سعر السكن المذكور أعلاه ، يتم تعيين وزن لكل بكسل.
لنفترض أننا حصلنا على صورة ، نحتاج إلى حساب احتمال أن يكون 8 ، والذي يتم تحويله إلى صيغة رياضية على النحو التالي:
يمثل i في الصيغة الرقم الذي سيتم توقعه (8) ، والذي يمثل قيم الوزن المختلفة لميزات 784 عندما يكون الرقم المتوقع هو 8 ، ويمثل انحياز 8 ، و X هي قيمة 784 سمة من سمات الصورة. من خلال الحساب أعلاه ، يمكننا الحصول على مجموع الدليل (الدليل) على أن الصورة هي 8 ، ويمكن لوظيفة softmax تحويل هذه الأدلة إلى احتمالية y. (المبدأ الرياضي لبرنامج softmax ، يرجى التحقق من المعلومات ذات الصلة بشدة)
تلخيص العملية السابقة في صورة (من المسؤول) كما يلي:
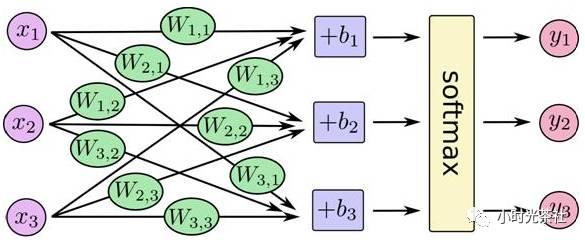
يتم ضرب وتلخيص الميزات المختلفة x والأوزان المقابلة لأرقام مختلفة للحصول على احتمالية التوزيع لكل رقم ، وتعتبر القيمة ذات الاحتمال الأعلى نتيجة لتوقع الصورة لدينا.
يمكن كتابة العملية المذكورة أعلاه كمعادلة على النحو التالي:

يمكن التعبير عن هذه المعادلة بكل بساطة في ضرب المصفوفة ، وهو ما يعادل:

بدون توسيع القيم المحددة في الداخل ، يمكن تبسيطها إلى:
إذا كان لدينا دراسة مناسبة للمحتوى المرتبط بالمصفوفة في الجبر الخطي ، فسوف نفهم في الواقع أن تعبير المصفوفة أسهل للفهم في بعض المسائل. لا يهم إذا كنت لا تتذكر محتويات المصفوفة ، فسوف أرفق مقطع فيديو للجبر الخطي لاحقًا.
على الرغم من أن الكثير قد قيل من قبل ، في الواقع ، فإن رمز المفتاح يتكون من أربعة أسطر:
تتشابه الأكواد المذكورة أعلاه مع العناصر النائبة المتغيرة ، فقم أولاً بتعيين طريقة حساب النموذج. في عملية التدريب الحقيقية ، تحتاج إلى قراءة بيانات المصدر على دفعات وتعبئتها بالبيانات باستمرار ، حتى يتم تشغيل حساب النموذج بالفعل. tf.zeros يعني ، أولاً قم بتعيين قيمة موحدة من 0 عناصر نائبة. تتم قراءة بيانات X من ملف البيانات ، بينما يتم تغيير وتحديث w و b باستمرار أثناء عملية التدريب ، ويتم حساب y بناءً على البيانات السابقة.
3. وظيفة الخسارة وإعدادات التحسين
لتدريب نموذجنا ، نحتاج أولاً إلى تحديد مقياس لقياس ما إذا كان هذا النموذج جيدًا أم سيئًا. يسمى هذا المقياس التكلفة أو الخسارة ، ثم حاول تقليل هذا المقياس. ببساطة ، نحتاج إلى تقليل قيمة الخسارة ، فكلما قلت قيمة الخسارة ، اقترب نموذجنا من النتيجة الحقيقية للملصق.
دالة الخسارة المستخدمة في العرض التوضيحي هي "إنتروبيا متقاطعة" ، وصيغتها على النحو التالي:
y هو التوزيع الاحتمالي لتوقعاتنا ، و y هو التوزيع الفعلي (كما دخلنا) ، والنتروبيا هو مقياس لعدم دقة تنبؤاتنا. يحتوي TensorFlow على رسم بياني يصف كل وحدة حسابية ، وهو التدفق الحسابي للنموذج بأكمله ، ويمكنه تلقائيًا استخدام خوارزمية backpropagation لتحديد كيفية تأثير المتغيرات مثل الأوزان على المتغير الذي نريد تقليل قيمة الخسارة. بعد ذلك ، سيستخدم TensorFlow خوارزمية التحسين التي قمنا بتعيينها لتعديل المتغيرات باستمرار لتقليل قيمة الخسارة.
من بينها ، يستخدم العرض التوضيحي خوارزمية نزول متدرج لتقليل الانتروبيا المتقاطعة بمعدل تعلم 0.01. تعد خوارزمية النسب المتدرج عملية تعلم بسيطة ، ولا يحتاج TensorFlow إلا إلى تحديث كل متغير شيئًا فشيئًا في اتجاه تقليل قيمة الخسارة.
رمز المفتاح المقابل هو كما يلي:
ملاحظات:
في الكود ، سترى المفهوم والاسم المتغير لمتجه واحد ساخن. في الواقع ، هذا شيء بسيط للغاية ، وهو تعيين مصفوفة من 10 عناصر ، واحد منها فقط هو 1 ، والآخرون 0 ، وذلك لتمثيل نتيجة التسمية للرقم.
على سبيل المثال ، قيمة تسمية تمثل الرقم 3:
4. عمليات التدريب واختبار دقة النموذج
من خلال التطبيق السابق ، قمنا بإعداد "مخطط انسيابي" للحساب للنموذج بأكمله ، وأصبحوا جميعًا جزءًا من إطار عمل TensorFlow. لذلك ، يمكننا بدء برنامجنا التدريبي ، ومعنى الكود التالي هو تدريب نموذجنا 500 مرة في حلقة ، مع أخذ 50 عينة تدريب على دفعات في كل مرة.
عملية التدريب هي في الواقع عملية تدريب على بدء التشغيل لإطار عمل TensorFlow. وخلال هذه العملية ، يقوم Python بدفع البيانات إلى المكتبة الأساسية للمعالجة.
لقد أضفت سطرين من التعليمات البرمجية إلى العرض التوضيحي الرسمي ، وقمت بحساب دقة التعرف على النموذج الحالي كل 50 مرة. إنه ليس رمزًا ضروريًا ، فهو يستخدم فقط لتسهيل ملاحظة التغيير التدريجي لدقة التعرف على النموذج بأكمله.
بالطبع ، يجب تحديد متغيرات مثل الدقة (دقة التنبؤ) المتضمنة فيها في المكان السابق:
عندما ننتهي من التدريب ، حان الوقت للتحقق من دقة نموذجنا ، كما كان من قبل:
نتائج التشغيل التجريبي الخاص بي هي كما يلي (مثال انحدار softmax يعمل بسرعة نسبيًا) ، ومعدل الدقة الحالي هو 0.9252:

5. طريقة عرض قيمة المعلمة في الوقت الفعلي
عندما بدأنا تشغيل العرض التوضيحي الرسمي لأول مرة ، أردنا دائمًا طباعة قيم المتغيرات ذات الصلة لمعرفة التنسيق والحالة. من الشفرة التجريبية ، يمكننا رؤية الكثير من كائنات متغير Tensor. في الواقع ، لا يمكن إخراج هذه الكائنات المتغيرة وعرضها بشكل مباشر. تقريبًا ، بعضها مجرد عناصر نائبة. إذا قمت بإخراجها مباشرة ، فستحصل على كائن مشابه لما يلي :
Tensor ("يساوي: 0" ، الشكل = (؟،) ، نوع dtype = منطقي)
نظرًا لأنه عنصر نائب ، يجب علينا إطعامه ببعض البيانات حتى يتمكن من عرض المحتوى الحقيقي. لذلك ، فإن الطريقة الصحيحة هي عادةً إضافة بيانات الإدخال الحالية إليها عند الطباعة.
على سبيل المثال ، انظر إلى البيانات الاحتمالية لـ y:
print (sess.run (y، feed_dict = {x: batch_xs، y_: batch_ys}))
يمكن أيضًا إخراج بعض المتغيرات غير النائبة مثل هذا:
طباعة (دبليو إيفال)
بشكل عام ، معدل دقة التعرف 92 مخيب للآمال نسبيًا.لذلك ، فإن MNIST الرسمية لديها بالفعل إصدارات مختلفة من النماذج المختلفة. من بينها ، إصدار CNN (الشبكة العصبية التلافيفية) ، وهو أكثر ملاءمة لمعالجة الصور ، يمكنه الحصول على 99 معدل الدقة أكثر من ، بالطبع ، وقت تنفيذه طويل نسبيًا.
(ملاحظة: cnn_mnist.py هو إصدار الشبكة العصبية التلافيفية ، ويوجد عنوان URL للتنزيل مرفق بقرص الشبكة السحابية الصغيرة)
إصدار الشبكة العصبية للتغذية الأمامية من MNIST ، حتى 97:

مشاركة البيانات وكود المصدر على Weiyun:
(ملاحظة: التنزيل من مواقع الويب الأجنبية بطيء نسبيًا. سيكون التنزيل أسرع نسبيًا. عند إعداد البيئة ، ما عليك سوى تنفيذ run.py بالداخل)
5. العرض التوضيحي مع سيناريوهات الأعمال: توقع ما إذا كان المستخدم عضوًا متميزًا
وفقًا للمحتوى السابق ، نحن على دراية بنموذج الشبكة العصبية القائم على softmax المذكور أعلاه مع ثلاث طبقات فقط (الإدخال والمعالجة والمخرجات). لذا ، هل يمكن تطبيق هذا النموذج على سيناريوهات أعمالنا المحددة؟ هل هو صعب؟ للتحقق من ذلك ، أخذت بعض البيانات من الشبكة الحالية لإجراء هذا الاختبار.
1. إعداد البيانات

لقد التقطت بيانات مشاركة المستخدم لحدث تذكرة فيلم على شبكة مباشرة ، بما في ذلك الأزرار التي تم النقر عليها ، ومنصة الهاتف المحمول ، وعنوان IP ، ووقت المشاركة وغيرها من المعلومات. في الواقع ، معلومات هوية المستخدم مضمنة في هذه البيانات. على سبيل المثال ، يجب الحصول على بعض حزم الهدايا من خلال حالة العضو المتميز. إذا نقر المستخدم على هذا الزر لاستلامها بنجاح ، فيمكن أن يثبت أن هوية المستخدم يجب أن تكون عضوًا متميزًا الحالة. بالطبع ، أنا فقط أفرز بشكل حدسي ميزات البيانات هذه التي لا ترتبط ببعضها البعض مثل بيانات العينة لدينا ، ومن ثم فإن الملصق المقابل هو العضوية الفائقة.
نموذج البيانات المستخدم للتدريب هو كما يلي:
العمود الأول هو رقم QQ ، والذي يستخدم فقط للتعريف المعرفي. ويشير العمود الثاني إلى ما إذا كان عضوًا متميزًا أم لا ، والذي يتم استخدامه كقيمة لعلامة التدريب. وفيما يلي عنوان IP ، وبت علامة النظام الأساسي و سجل المشاركة للأنشطة المشاركة (0 يعني المشاركة غير الناجحة). ، 1 يعني المشاركة الناجحة). ثم تحصل على مصفوفة تحتوي على 11 ميزة (بعد بعض عمليات التحويل والتعيينات ، يتم تقليل الأعداد الكبيرة جدًا):
ما إذا كان تنسيق البيانات الفائقة المطابق كما يلي ، كتسمية للتعلم الخاضع للإشراف:
العضو المتميز:
عضو غير متميز:
نحتاج هنا إلى شرح الأسباب التي تجعل تحويل البيانات مطلوبًا في التطبيقات العملية على وجه التحديد. من ناحية أخرى ، يساعد تعيين هذه البيانات وتحويلها على تبسيط نموذج البيانات. من ناحية أخرى ، من أجل تجنب مشكلة NaN ، عندما تكون القيمة كبيرة جدًا ، في بعض عمليات الفاصلة العائمة للأس والقسمة الرياضية ، من الممكن الحصول على قيمة غير محدودة ، أو حالات تجاوز أخرى ، والتي ستصبح NaN في Python. ، سيؤدي هذا النوع إلى تدمير جميع نتائج الحسابات اللاحقة ، مما يؤدي إلى حساب غير طبيعي.
على سبيل المثال ، في الشكل أدناه ، قيمة الميزة كبيرة جدًا. أثناء عملية التدريب ، سوف تتراكم بعض المعلمات في الوسط أكثر فأكثر ، مما سيؤدي في النهاية إلى قيم NaN ، وسيتم تدمير جميع نتائج الحساب اللاحقة:

سبب NaN لانهائي أو صغير بلا حدود في الحسابات الرياضية المعقدة. على سبيل المثال ، في العرض التوضيحي الخاص بنا ، يرجع سبب إنشاء NaN بشكل أساسي إلى حساب softmax.
وقت التشغيل
عندما بدأت في تنفيذ تطبيقات الأعمال العملية لأول مرة ، وجدت أن النتائج الغريبة جدًا كانت غالبًا ما تنفد (وجدت أن البرنامج يمكن أن يستمر عندما واجهت مشكلة NaN). بالطبع ، بعد تحليل دقيق للمشكلة ، وجد أنه لا توجد طريقة للتحقيق. نظرًا لأن قيمة NaN هي نوع غريب ، يمكنك استخدام طريقة التشفير التالية NaN! = NaN لاكتشاف ما إذا كان NaN يظهر في عملية التدريب الخاصة بك.
رمز البرنامج الرئيسي هو كما يلي:

لقد استخدمت الطريقة المذكورة أعلاه ووجدت برنامج التعلم العميق الخاص بي بسلاسة شديدة ، أي مجموعة من البيانات أنتجت NaN. لذلك ، بالنسبة للعديد من البيانات الأولية ، سنقوم بالقسمة على قيمة معينة لجعل القيمة أصغر. على سبيل المثال ، يقوم MNIST الرسمي أيضًا بهذا ، حيث يقسم قيمة اللون 256 بكسل بشكل موحد على 255 ، بحيث تصبح جميعها رقمًا عائمًا أقل من 1.
عندما تعالج MNIST بيانات ميزة البكسل للصورة الأصلية ، فإنها تقلل أيضًا من بيانات الميزة:

ذات مرة أزعجتني مشكلة قيمة NaN بشدة (الماضي لا يطاق -__- !!) ، خاصةً وضعه هنا لتجنب دخول الطلاب المبتدئين إلى الحفرة.
2. نتيجة التنفيذ
مجموعة التدريب (6700) ومجموعة الاختبار (1000) التي أعددتها ليست بيانات كثيرة ، لكن دقة التنبؤ بالعضوية الفائقة يمكن أن تصل في النهاية إلى 87. على الرغم من أن دقة التنبؤ ليست عالية ، فقد يكون هذا مرتبطًا بنقص البيانات في مجموعة التدريب الخاصة بي.ومع ذلك ، لم يستغرق النموذج بأكمله الكثير من الوقت ، من فرز البيانات ، والترميز ، والتدريب إلى النتيجة النهائية ، تم استخدام 2 فقط. وقت الليل.

يمثل الشكل أدناه مثالين فعليين للاختبار. على سبيل المثال ، يتنبأ النموذج بأن أول مستخدم QQ لديه احتمال 82 بأن يكون مستخدمًا غير متميز العضوية واحتمال 17.9 أن يكون مستخدمًا متميزًا (التنبؤ دقيق) .
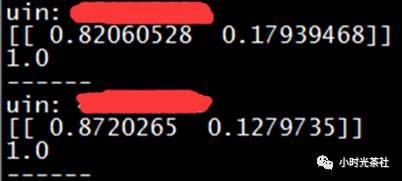
من خلال المثال أعلاه ، سنجد أنه بالنسبة لبعض السيناريوهات البسيطة نسبيًا ، يمكننا تنفيذها بسهولة نسبيًا.
6. نماذج أخرى
1. CIFAR-10 عرض تصنيف الصور (رسمي)
يعتبر التصنيف في مجموعة بيانات CIFAR-10 مشكلة مرجعية مفتوحة في التعلم الآلي ، وتتمثل مهمتها في تصنيف مجموعة من الصور 32x32RGB تغطي 10 فئات: طائرة ، سيارة ، طائر ، قطة ، غزال ، كلب ، ضفادع ، خيول ، قوارب وشاحنات .
هذا أيضًا أحد العروض التوضيحية الرسمية المهمة.

مقدمة أكثر تفصيلاً:
عملية تنفيذ هذا المثال طويلة نسبيًا وتتطلب الصبر.
عملية التنفيذ والنتائج على الجهاز:
يستخدم cifar10_train.py للتدريب:

يستخدم cifar10_eval.py لاختبار النتائج:
معدل التعرف ليس مرتفعًا لأن معدل التعرف على النموذج الرسمي ليس مرتفعًا:

بالإضافة إلى ذلك ، عندما قمت بتشغيل المثال الرسمي لأول مرة في الخامس من يناير ، كانت لا تزال هناك بعض المشكلات الصغيرة ولم أتمكن من تشغيله (ربما تم تصحيح أحدث مثال رسمي). يوصى باستخدام الإصدار الذي وضعته على Weiyun مباشرة (في الكود). يجب تعديل السجل والمسار لقراءة الملف).
لا يحتوي قرص السحابة الصغيرة على بيانات الصورة الخاصة بمجموعة التدريب ومجموعة الاختبار. ومع ذلك ، إذا اكتشف البرنامج أن هذه الصور غير موجودة ، فسيقوم بتنزيلها بنفسه:

2. ما إذا كان الاختبار التجريبي أقدم من 5 سنوات
من أجل اختبار ما إذا كان نموذج انحدار softma يمكنه تعلم بعض القواعد التي أضعها بنفسي ، قمت بعمل عرض توضيحي صغير للاختبار. لقد قمت بإنشاء سلسلة من البيانات من خلال توليد الأرقام العشوائية ، ودع نموذج انحدار softmax السابق يتعلم ، وأخيرًا معرفة ما إذا كان النموذج يمكنه اجتياز تعلم مجموعة التدريب ، وأخيراً توقع 100 ما إذا كانت بيانات العينة أقدم من 5 سنوات.
النموذج والبيانات نفسها بسيطة نسبيًا ، طريقة بناء البيانات:
أقوم بإنشاء عينة بيانات بشكل عشوائي باستخدام خطي عرض خاصيتين فقط ، حيث تأخذ السنة القيمة 0-10 بشكل عشوائي ، ويتم وضع الرقم 1 كتداخل.
إذا كانت السنة أكبر من 5 سنوات ، يتم تعيين الملصق على :؛
وبخلاف ذلك ، يتم تعيين التسمية على:.
أنتج 6000 مجموعة تدريب وهمية لتدريب النموذج ، وأخيرًا يمكنه تحقيق دقة تنبؤ ناجحة بنسبة 100:

تحميل Weiyun (تنزيل الكود المصدري):
3. تعلم الشعر القديم القائم على RNN
إن أول ذكاء اصطناعي يكتب قصائد قديمة مذهل للغاية ، وقد تم إجراء العرض التوضيحي بواسطة باحث في الولايات المتحدة ، ويمكنه إنشاء قصائد قديمة لا يمكن أن تستند إلى الموضوع ، كما أن جودة القصائد القديمة عالية نسبيًا. لذا ، حاولت أيضًا تشغيل نموذج يمكنه كتابة قصائد قديمة على جهازي ، ثم وجدت نموذجًا يعتمد على RNN. الشبكات العصبية المتكررة RNN هي واحدة من أكثر نماذج التعلم العميق شيوعًا. بناءً على عرض توضيحي خارجي ، أجريت بعض التعديلات وقمت بتشغيل برنامج بسيط نسبيًا يمكنه تعلم وكتابة القصائد القديمة.
قم بكتابة القصائد (دعها تكتب عشرة):
-
بقيت يي دي في لينجشوي ، كما أن إرشوان يحسد أسرة ووهو. قال ليو القديم إن جثة أحد العلماء كانت مصبوغة ، وأن الخوخ والبرقوق زُرعا في الغابة ليتم تسميتهما بالمنزل. إذا نظرنا إلى الوراء في اليوم الذي كان فيه Er Mao ضيقًا في التنفس ، فإن الطبيعة الخالدة لـ Wan Dang كانت غير راغبة تمامًا. كيف صهل يوما وبكى ، لا أصدق Hongfeng Yicunxi.
-
المعبد المهجور ، يشبه قمر الصنوبر والين سماء فارغة ، والرياح ترتفع وضوء المساء يحث. لم يكن Wu Xin يكره مسار البخور ، وكان من الواضح جدًا مغادرة Ding Cangzhou. يطارد "لان" فراشة الفأس المجاورة ذات الرأس الأبيض ، والطريق الأخضر للعودة هو من "تشينغاي". إذا أراد الحطاب الذي يصطاد السمك أن يغير حسد يانغ ، فإن نهر قويوان الغربي يأتي إلى بيشو.
-
في السماء البعيدة ، سقطت الزهور على Wushan ، و Feng Pei ركض بعيدًا عن Chengzhuang. كان Cui Chu مثل شرب القليل من الطاقة ، وفي الشهر الماضي ، كان الفرن الأحمر ثورًا ثقيلًا. حث شيانغ تشو تشو على أن يكون مع الضيف الافتراضي ، وملأ شي شي المبنى للحصول على روي هونغ. الجملة الجيدة تعني من الصندوق الشفاف القديم ، والأقحوان تزدهر عندما تقطع.
-
المنخفض على النهر هو أول من أخذها ، والاسم يسبح منذ بداية الشهر. تقع عدة أقدام من سحب Wen Gao على بعد مسافة بعيدة ، وهناك العديد من الأشباح في بلدة Fangchuan. عندما تتحرك الرياح الغربية على عتبة الاجتماع ، لا تستمع إلى الريح والدخان للتعرف على الصيد. كان يجب أن تحلم كتاكيت Tifee بالأمس ، وستكون مليئة بالغبار الغامض منذ ذلك الحين.
-
عندما يتجنب حياته ويلقي ظهره عند الغسق ، انظر من في سيتشوان يبكي ويحلم بمعرفة العام. ومع ذلك ، كان العيد مريبًا وسلبيًا ، ولم يكن هناك ربيع في سلالات جيا وتانغ. يلقي الشيطان السري القديم نظرة خاطفة على ضريبة الحجر ، ويجب أن يستمع Hecheng إلى السحب البيضاء. عندما طاف الصباح إلى الشاطئ ، كرهت البوم ، ولم تستمع إلى تشينغتشينغ لطول المسار.
-
ما تبقى من Chu Tian كثيف للغاية ، والجزء العلوي من رذاذ بارد لآلاف الأميال. المئات من الأوراق الطويلة لا تنتهي ، والماء مليء بالقمم المتبقية في ليلة الربيع. الرياح والأمواج على رأس البحيرة منحدرة وتقرع الطبول ، ولا يقع North Que في قرية Chuli. هناك ثلاثة عملاء في أربعة أيام ، وتقاتل البكرات للحصول على الدعم للوصول إلى Danchi.
-
عندما تضافرت أيدي Chongmen التسعة أيام ، يجب أن يتعطش Yin Suspicion ليقول وداعًا لـ Jin Xiang. لا يزال الصيد مقيدًا حول الشاي والنبيذ ، ويتم حرق الملابس بفظاظة. رفض Ziming الشك في يوم النعمة ، وكان Qinguan Hanlin متلهفًا للصقيع المسائي. عبر فمه وغمر نفسه في نهاية المحظية الانفرادية ، وخرج إلى Xie Kongqing لإرسال آلة فضية. لا يكفي ضريح اللوتس ليكره الحرير ، وتطبق Hua Qi السندان للخروج من صخرة الصيد.
-
من أجل تلبية الخشب القديم في المأدبة ، لا يمكن إغلاق طريق Ronghua. عندما يكون الوقت خاملًا ، هناك وقت طويل بعد الحجر ، والماء الداكن والأفق دافئ الناس. تهب الرياح الصقيع والزهور تعوي المرآة. كان هو لاوشيانغ يستمع للخادم الحقيقي ، وكان شيشيبانتشانغ هو الحافر السياسي القديم.
-
رأيت Zhu Lan خارج بلدة Tingjin ، وأحيانًا كان الجزء الشمالي من الغرفة ممتلئًا بالبخور. يوجد خارج الباب بيت الزهور القديم في مذبح اليشم ، وسترتفع بطاقة البخور بمجرد خروجها. يبيع جسر الضريح Cuidai الخالد بشكل رائع ، ويتلقى Xiao ظلال المبنى الحمراء المتداخلة. إذا كنت تجرؤ على وضع الشائعات المرة في ذهب ، فعليك أن تتبع كيجيان وحده.
-
كان ازدهار وانحدار الأمس هما الخوخ و Li Qing ، وتم غزو عناد Zi Liu. يكمن الخطر في أن النهر ينحدر على سطح القمر ، وأن الدخان والأمواج في مقاطعة هان بيضاء. لا يزال جناح مينجيوي الذي لا يزال ختم المقاطعة ، لا أعرف من هو المخطئ. إنه أمر محرج أكثر أن ترسل Feng Hen ، أخشى أن تكون كتكوت الحوت هي الملكة.
بالإضافة إلى ذلك ، قمت باستخراج بعض الآيات التي أعتقد شخصياً أنها أفضل كتابتها (تلك التي نفدت من قبل ، وليست في الصورة أعلاه):

النموذج بسيط نسبيًا ، ومستوى كتابة الشعر ليس جيدًا مثل العرض التوضيحي للباحث الأمريكي الذي قدمته سابقًا ، لكن الطريقة الأساسية المستخدمة يجب أن تكون متشابهة ، لكن ما يفعله هو أكثر تعقيدًا.
بالإضافة إلى ذلك ، هذا نموذج عام يمكنه تعلم محتوى مختلف (الشعر القديم ، الشعر الحديث ، شعر الأغنية أو الشعر الإنجليزي ، إلخ) ، ويمكن أن يولد نتائج مماثلة.
7. تجربة التعلم التمهيدي للتعلم العميق
1. الذكاء الاصطناعي وتكنولوجيا التعلم العميق ليسا غامضين ، فهما أشبه بنوع جديد من الأدوات ، فمن خلال تغذيتها بالبيانات ، يمكنها اكتشاف القوانين الكامنة وراء البيانات واستخدامها لنا.
2. يعتبر الأساس الرياضي أكثر أهمية ، مما يساعد على فهم المبادئ الرياضية وراء النموذج. ومع ذلك ، من وجهة نظر تطبيقية بحتة ، ليس من الضروري إتقان الرياضيات بشكل كامل ، ويمكنك أيضًا البدء في إجراء بعض التجارب والتعلم مقدما.
3. أشعر بعمق بنقص موارد الحوسبة. بعد تعديل معلمات البرنامج أو بيانات التدريب ، غالبًا ما يستغرق الأمر عدة ساعات لتشغيل مجموعة التدريب.بعض السيناريوهات لا تقوم بتشغيل المزيد من بيانات مجموعة التدريب ، ولا يوجد فرق. مثال حالة كتابة الشعر. شخصيًا ، هذه مشكلة مهمة تقيد تطوير الذكاء الاصطناعي ، وهي تجعل "تصحيح أخطاء" البرنامج بشكل مباشر غير فعال للغاية.
4. هناك عدد قليل نسبيًا من المستندات الصينية وليس العديد من المستندات الإنجليزية ، فقد تم تحديث مجتمع المصادر المفتوحة بسرعة ، وأصبح محتوى المستندات قديمًا نسبيًا بسرعة. لذلك ، هناك العديد من المشاكل التي تمت مواجهتها عند البدء ، وهناك نقص في الوثائق المُشكَّلة.
8. ملخص
لا أعرف ما إذا كان عصر الذكاء الاصطناعي سيأتي حقًا ، أو إلى أين يتجه ، ولكن لا شك في أنها طريقة جديدة تمامًا للتفكير في التكنولوجيا. لطالما كان الغرض الأساسي لمهندسينا هو استكشاف هذه التكنولوجيا الجديدة وتعلمها بشكل أفضل ، ثم البحث عن نقطة دمج في سيناريوهات تطبيق الأعمال ، وفي النهاية مساعدة أعمالنا على تحقيق نتائج أفضل. من ناحية أخرى ، عادةً ما تتطور التقنيات الجديدة التي لها دور رئيسي في تعزيز التنمية بسرعة وتصبح شائعة ، تمامًا مثل برامجنا. لذلك ، يمكن للجميع القيام بتطبيقات التعلم العميق ، وليس مجرد وسيلة للتحايل.
الوثائق المرجعية:
المحتوى المتعلق بالرياضيات:
أقسام المدرسة الثانوية والكلية