
هذه المادة هي ICLR رقة 2020 "V4D: 4D التلافيف الشبكات العصبية لمستوى التمثيل فيديو التعلم"، رمز مؤلف من تقنية طويلة.
على | طويلة ساحة تقنية تحرير | نهاية كونغ

عنوان ورقة: الشبكي: //arxiv.org/abs/2002.0744
معظم الفيديو 3D التفاف الشبكة العصبية للتعلم هي النهج القائم على مقطع لا تعتبر الخصائص المكانية والزمانية من التغييرات على مستوى الفيديو. نقترح مستوى الفيديو من الشبكة العصبية التفاف رباعية الابعاد، ويشار إلى V4D، واستخدام رباعي الأبعاد التفاف الزمكان إلى نموذج لمسافات طويلة تمثل التغيير، مع الاستفادة من بنية المتبقية لعقد الخصائص المكانية والزمانية ثلاثية الأبعاد. قدمنا المزيد من التدريب V4D والمنطق. أجرينا عددا من التجارب على ثلاثة الفيديو لفهم عملية جمع البيانات، V4D حققت نتائج جيدة وتجاوز شبكة التفاف 3D.
1 مقدمة
يستخدم الشبكة العصبية 3D أساسا لشظايا ومتغيراتها حيث مرحلة التعلم، بدلا من التدريب الفيديو بأكمله. أثناء التدريب، استنادا إلى شظايا عشوائية عينات من شرائح فيديو كليب (على سبيل المثال، 32) ليدل على التعلم. أثناء الاختبار، ويتم أخذ عينات بشكل موحد من تعددية كاملة من شرائح الفيديو عن طريق انزلاق النافذة، وعشرات توقع حساب مستقل لكل جزء. وأخيرا، فإن متوسط الدرجات لجميع مقاطع الفيديو وتوقع، الحصول على نتائج التنبؤ الأفقية الفيديو. خلال التدريب، ويتجاهل هؤلاء نموذج قائم على مقطع هيكل على مستوى الفيديو من الزمكان والتي تعتمد على المسافة، لأنها عينة سوى جزء صغير من الفيديو بأكمله. وفي الوقت نفسه، أثناء الاختبار، قد يكون كل بسيطة متوسط درجات التنبؤ شظايا دون المستوى الأمثل. للتغلب على هذه المشكلة، وشرائح وقت الشبكة (TSN) أخذ العينات وافر من شرائح موحد من الفيديو بأكمله، واستخدامها لتوجيه متوسط درجة من العملية التدريبية العودة نشر. ولذلك، TSN هو إطار التعلم التمثيل على مستوى الفيديو. ومع ذلك، تم إجراء الانصهار التفاعلية وبين الإطار TSN الفيديو المستوى إلا في مرحلة متأخرة جدا، فإنه لا يمكن التقاط الهيكل الوقت أدق.
يعرض المقال هذا، إطار التعلم تمثيل V4D العام مرونة مستوى الفيديو، كما هو مبين في الشكل. تصميم V4D يتكون من عنصرين هما مفتاح: (1) استراتيجية أخذ العينات بشكل عام؛ (2) 4D التفاف التفاعل. علينا أولا قدم استراتيجية أخذ العينات مستوى الفيديو، سلسلة من حدة يغطي على المدى القصير وأخذ عينات من الفيديو كله موحد. ثم، كتلة المتبقية 4D من خلال تصميم وتعتمد على النمذجة الزمنية بعيدة المدى. 4D كتلة المتبقية يمكن دمجها بسهولة في 3D CNN، هيكل في وقت سابق وأكثر بعدا من TSN على غرار القائمة. نحن أيضا تصميم V4D خوارزمية معينة الاستدلال مستوى الفيديو. على وجه التحديد، ونحن تحقق على المؤشر ثلاثة الفيديو الحركة الاعتراف بصحة V4D: ميني حركية-200، حركية-400 وشيء-شيء-V1. هيكل V4D على هذه المعايير لتحقيق أداء تنافسي للغاية، والوصول إلى رفع من 3D CNN.


الشكل 1: 4D الشبكات العصبية التلافيف على مستوى الفيديو للتعرف على الفيديو.
2 الأعمال ذات الصلة
العمارة للتعرف على الفيديو ويمكن تقسيمها إلى ثلاث مجموعات: مزدوجة CNN، 3D CNNs وإطار النمذجة على المدى الطويل.
2.1 شوانغليو CNN
واقترح بنية مزدوجة أولا سيمونيان وZisserman، حيث تدفق من الصورة RGB للتعلم، لنمذجة تدفق الآخر التدفق الضوئي. نتائج اثنين من تيارات الناتجة عن الانصهار في الآونة الأخيرة، للحصول على النتائج المتوقعة النهائية. تدفق بصري ومع ذلك، يتم احتساب العيب الرئيسي في كثير من الأحيان وقتا طويلا. وهناك أيضا بعض الأعمال التي ارتكبت مؤخرا لخفض تكلفة الحسابية من تدفق البصرية التناظرية. في مجال الفيديو تقدر مساهمة مزدوج والانصهار هو طريقة شائعة لتحسين دقة مجموعة متنوعة من التشكيلات، وأنه يقدم لنا V4D هي متعامد.
2.23D CNNs
3D CNN غالبا ما يكون أكثر من المعلمات، والحاجة إلى مزيد من التدريب البيانات لتحقيق الأداء العالي. التجارب الحديثة على مجموعات البيانات الكبيرة مثل حركية-400 يمكن عرض CNN 3D على 2D CNN، في معظم الحالات، حتى ضعف والقانون إلى حد ما. ومع ذلك، فإن معظم CNN 3D هو طريقة التي الوسائل، على أساس جزء أنه خلال مرحلة التدريب الذي استكشاف سوى جزء من الفيديو.
إطار النمذجة 2.3 طويل الأجل
وهناك بالفعل بعض الطرق لوضع إطار النمذجة طويلة الأجل لالتقاط هيكل وقت أكثر تعقيدا. وهناك طريقة لاستخدام 2D CNN مستوى الإطار استخراج ميزة، تسلسل مستمر من إطارات الفيديو يحسب الشبكة العصبية متكررة. استخدام TSN وتجميع أخذ عينات قليلة عينات قليلة المستخرجة من الإطار بأكمله من شريط الفيديو لمعرفة لتحديد مستوى الفيديو من آخر من هذه الحسابات، وبلغ متوسط لتوليد تحديد المستوى الفيديو. وعلى الرغم مصممة أصلا ل2D CNN، TSN ولكن أيضا يمكن تطبيقها على 3D CNN، يتم تعيينها إلى واحد من خط الأساس من هذه المادة. A TSN هي عيوب واضحة، ويرجع ذلك إلى متوسط البلمرة بسيطة، فإنه لا يمكن أن تكون على غرار الوقت هيكل أدق.
3 V 4 D
في هذا القسم، ونحن نقدم ل4D شبكة عصبونية التفافية جديدة لتحديد حركة الفيديو الفيديو، أي V4D. هذه هي المحاولة الأولى لتصميم 4D القائم على التفاف RGB الاعتراف الفيديو. القائمة 3D CNN كمدخل لشريحة قصيرة، لا يعتبر الخصائص المكانية والزمانية ثلاثية الأبعاد لتمثيل تطور طبقة الفيديو. على الرغم من أن تقوم شبكة غير محلي الاتفاق المعمم غير محلي شبكة والآليات المقترحة لنموذج غير ذاتية الانتباه الخصائص المكانية والزمانية المحلية، ولكن هذه الأساليب على قطاع التصميم الأولي 3D CNN. وليس من الواضح كيف هذه العملية في تمثيل الفيديو العام، وهذه العملية مفيدة للتعلم على مستوى الفيديو. مزيد من غير محلي تطبيقها مباشرة لحساب مقدار الفيديو كامل مرتفع نسبيا. هدفنا هو تصميم كمية قليلة من حساب والتحسين السهل للنموذج الزماني المكاني على المدى الطويل. في هذا العمل، ونحن نقدم كتلة المتبقية 4D و 3D CNN المتوقع 4D CNN من أجل معرفة 3D ميزات تفاعلية عن بعد، مما أدى إلى "وقت للوقت" التمثيل مستوى الفيديو.
3.1 فيديو استراتيجية أخذ العينات مستوى
نماذج للعمل لتحديد تمثيل فعال مستوى الفيديو، للدخول إلى الشبكة لتغطية كامل مدة الفيديو معين، مع الحفاظ على تفاصيل عمل قصيرة الأجل. في هذا العمل، ونحن تقسيم بالتساوي الفيديو بأكمله، ويتمثل جزء تم اختيارها عشوائيا من كل قطعة من وضع التشغيل على المدى القصير، ويشار إلى "وحدة العملية." ثم نستخدم سلسلة من الإجراءات في وحدة فيديو لتمثيل العملية برمتها.
3.2 للتفاعل والتعلم 4D الزمكان الإلتواء
وقد اقترح ثلاثي الأبعاد نواة الالتواء لسنوات عديدة، والنمذجة على المدى القصير من الخصائص المكانية والزمانية يكون لها دور قوي. ولكن نظرا لصغر حجم جوهر ثلاثي الأبعاد، الحقل تقبلا ثلاثة الأساسية غالبا ما تكون محدودة، وتجميع عادة الحد الأقصى لتوسيع مجال تقبلا، مما أدى إلى فقدان المعلومات. هذا من وحي لنا لتطوير عمليات جديدة، قصيرة وطويلة الأجل يمكن أن تكون على غرار تمثيل الزمان والمكان، هو الأمثل سهل وسريع من التدريب في نفس الوقت. من هذا المنظور، فإننا نقترح 4D التفاف أفضل لنمذجة التفاعل الزمكان بعيدة المدى.
ونحن نعرف حجم المدخلات (C، U، T، H، W)، حيث C هو رقم القناة، U هو عدد وحدات تشغيل، T، H، W يمثل طول الوقت، وارتفاع وعرض كل وحدة العملية. بكسل إخراج تقع في (ش، ر، ح، ث) تابعة لي-ث القناة
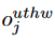
ممثلة، 4D يمكن أن تكون ممثلة على النحو التفاف

وبسبب الالتواء هو عملية خطية، فمن الممكن لتبادل ترتيب الجمع، وبالتالي الحصول على المعادلة (2)

إشعار داخل العملية بين قوسين هو في الواقع عملية التفاف 3D، لذلك في الواقع 4D 3D الإلتواء يمكن تنفيذها من قبل التفاف. هذا هو حال معظم الأطر التعلم عميقة لا توفر عمليات 4D، كيف نحقق 4D الإلتواء.
وبالإضافة إلى ذلك، في الشكل 2 نحن 4D التصور عدة سلوك التفاف نواة وبالمقارنة مع التفاف نواة 3D، كما هو موضح في تمثل الأزرق حبات الإلتواء، يمثل اللون الأخضر وسط نواة الالتواء.

الشكل 2: تنفيذ حبات 4D، مقارنة مع 3D نواة الصورة U يدل على عدد من وحدات العمل، مع شكل T، H، يتم حذف أبعاد W قناة دفعة ولوضوح يتم تلوين وحبات في الزرقاء، مع مركز ... كل نواة الملونة باللون الأخضر.
مقارنة مع التفاف ثلاثي الأبعاد، والالتواء لدينا المقترحة 4D الفيديو يمكن أن تكون على غرار في 4D الفضاء ميزة أكثر وضوحا، مما يجعل من الممكن لدراسة أكثر تعقيدا ثلاثي الأبعاد الزمكان التفاعل عن بعد التمثيل. ومع ذلك، 4D التفاف إدخال حتما أكثر من المعلمات وحساب التكلفة. في الممارسة العملية، من أجل 4D التفاف نواة ك ك ك ك سبيل المثال، أن يكون أكثر من الأوقات ك 3D التفاف نواة المعلمة ك ك ك، لذلك نحن أيضا ك ك 1 1 وك 4D حبات 1 1 1 يتم استكشاف للحد من المعلمات لتجنب مخاطر الإفراط في تركيب.
3.3 مستوى الفيديو العمارة 4D CNN
نحن التفاف 4D تضاف إلى الهيكل القائم CNN. للاستفادة الكاملة من التيار أفضل 3D CNN، نقترح حدة 4D المتبقية، الأمر الذي يجعل الفيديو أثناء مستويات باختصار تعلم وطويلة تتراوح التغيرات الزمانية ممكن. على وجه الخصوص، أن نحدد وظيفة التبديل،
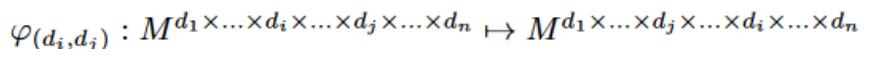




بين

4D هو عملية التفاف،

المدخلات والمخرجات، من خلال تبادل فاي وظيفة لضمان الاتساق في المدخلات والمخرجات الأبعاد.
من الناحية النظرية، يمكن أن يتوقع أي هيكل ثلاثي الأبعاد على CNN CNN 4D 4D من خلال كتلة التفاف متكامل. كما هو مبين في الأعمال السابقة التي الإلتواء ثنائي الأبعاد وانخفاض طبقة في التفاف ثلاثي الأبعاد تطبيقات طبقة أعلى يمكن الحصول على أداء أفضل. في إطار لدينا، كنا Slowpath من Feichtenhofer وغيرها لدينا العمود الفقري، كما يختصر I3D-S. على الرغم من أن Slowpath الأولية لتصميم resnet50، لكننا يمكن أن تمتد إلى I3D-S resnet18 مزيد من التجارب. لدينا مفصل 3D هيكل العمود الفقري كما هو مبين في الجدول رقم 1.

3.4 والتدريب المنطق التدريب
طريقة التدريب: 1، والتفاف طبقة الشبكة والتفاف الكتل المتبقية 3D 4D المقترحة. كل وحدة العمليات وعلى التوالي موازية ويشتركون في نفس التدريب المعلمة طبقة التفاف الأبعاد. وتحسب من كل من هذه الوحدات العمل الفردية 3D الميزات ثم الإسهام في كتلة المتبقية 4D، لمحاكاة عملية مستمرة على المدى الطويل لتطور وقت الوحدة. وأخيرا، فإن سلسلة من تشغيل جميع تنطبق متوسط الخلية وحدة العالمية، وتشكيل تمثيل مستوى الفيديو.
المنطق:

3.5 مزيد من النقاش
في هذا القسم، وسوف نعرض V4D يمكن أن ينظر إلى التوسع المقترح كوسيلة تستخدم على نطاق واسع في السنوات الأخيرة،
شبكة الفترة (1) وقت
نحن ترتبط ارتباطا وثيقا الفترة الزمنية من V4D شبكة (TSN)، على الرغم من أن صممت في البداية ل2D CNN، ولكن TSN يمكن تطبيقها مباشرة إلى 3D CNN التمثيل على غرار مستوى الفيديو. خلال التدريب، ويتم احتساب كل قطعة على حدة، ثم بعد عشرات توقع متوسط طبقة متصلة بشكل كامل. منذ طبقة اتصال كاملة هي عملية الخطية، حتى بعد طبقة اتصال كامل (على غرار avgpool العالمي) أو طبقات مرتبطة ارتباطا كاملا (TSN مماثل) بحساب قيمة متوسط يعادل رياضيا. وبالتالي، إذا تم تعيين كافة المعلمات 4D كتلة الصفر، فإننا يمكن اعتبار V4D 3D CNN + TSN.
(2) توقيت التفاف جوفاء
وخاصة 4D التفاف النواة، يرتبط ارتباطا وثيقا kx1x1x1، وتوقيت التفاف فارغة. عندما يتم توصيل مستوى الفيديو من جميع وحدات التشغيل معا في البعد الزمني، وتمثيل المدخلات يمكن اعتبار (C، UxT، H، W) هو موتر. في هذه الحالة، kx1x1x14D الإلتواء من تجويف يمكن اعتبار T والإلتواء kx1x13D. وبطبيعة الحال، 4D التفاف kx1x1x1 هو أبسط شكل نواة الإلتواء 4D، 4D أخرى، أكثر تعقيدا نواة الالتواء لا يمكن تفسيره بهذه الطريقة. وبالإضافة إلى ذلك فإننا نقترح 4D كتلة المتبقية يحتوي على هيكل المتبقية، بحيث الفيديو وهيكل هيكل قصيرة المكانية والزمانية قد تكون طويلة في الوقت الذي تعلم، والذي هو تسلسل وجود أي وظيفة التفاف جوفاء.
التجربة 4
4.1 الإدراجات
نحن أجريت على ثلاث اختبار لقياس الأداء القياسية: ميني حركية-200، حركية-400، شيء، شيء-V1. ميني حركية الطبقة العمل 200 تحتوي، حركية-400 هي مجموعة فرعية. وبما أن بعض البيانات المفقودة حركية مجموعات البيانات، لدينا نسخة من حركية-400 مجموعة تحتوي على 240436 و19796، على التوالي، في مجال التدريب فيديو والطفل التحقق من الصحة. ويشمل ميني حركية نسخة 78422 أشرطة فيديو للتدريب و4994 للتحقق من الفيديو. كل فيديو حوالي 300. يحتوي على شيء، شيء-V1 الفيديو ما مجموعه 108499، منها 86017 لتدريب 11522 للتحقق، 10960 للاختبار. كل فيديو له 36-72.
4.2 التجارب ميني حركية
نحن نستخدم الأوزان تدريب قبل من التهيئة نموذج ImageNet. للتدريب، ونحن نستخدم استراتيجية المعاينة الشاملة المذكورة في القسم 3.1. نحن بالتساوي تقسيم الفيديو بأكمله إلى القسم U، وحدد شريحة من كل 32 جزء عشوائيا. لكل قطعة، ونحن عينات بشكل موحد 4، ثابتة الخطوة 8، تشكيل وحدة الحركة. سندرس آثاره في التجارب التالية. علينا أولا ضبط حجم كل إطار 320 256، ثم قص عشوائيا، ثم منطقة خفض التدريجي هو مزيد من تعديلها إلى 224 224. نحن نستخدم SGD محسن، ومعدل التعلم الأولي هو 0.01، والوزن توهين ل
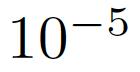
الزخم هو 0.9. انخفض 35،60،80 معدل التعلم 10 مرات، وتم تدريب 100 نماذج دورات.
للمقارنة عادلة، ونحن نتابع غير محلي وSlowfast تستخدم FCN اختبار. استخرجنا موحد من وحدة العملية برمتها تغطية 10 ينفذ المكانية مع كل وحدات العمل 3256 256 منطقة، ثم V4D المنطق. علما بأن لTSN من الأصل، واستخدام شرائح 25 والمنطق 10-المحاصيل خلال الاستدلال. لI3D مقارنة عادلة وV4D، ونحن أيضا استخدام FCN اختبار هذا 10 قطاعات واستراتيجيات التفكير 3-المحاصيل لTSN.
النتائج. لV4D التحقق من صحة، ونحن سوف مقارنتها مع النهج القائم على جزء وطريقة-S I3D على الفيديو TSN + I3D-S كان. للتعويض عن معلمات إضافية أدخلت 4D كتلة، نضيف 3 3 3 كتلة المتبقية للمقارنة عادلة من Res4 I3D-S، كما أعرب عن I3D-S ResNet18 ++. كما هو مبين في الجدول. 2A، حتى V4D 4 مرات أقل من عدد الإطارات I3D-S المستخدمة في المنطق، ولكن أقل من المعلمة من I3D-S ResNet18 ++، V4D تزال أعلى دقة من 2 من I3D-S. طريقة ومستوى الفيديو مقارنة TSN + I3D-S، تحسنت V4D دقة 2.6.
4D التفاف نواة أشكال مختلفة. كما ذكر سابقا، يمكننا استخدام نواة الالتواء 4D ثلاثة أشكال نموذجية: ك 1 1 1، ك ك 1 1 وك ك ك ك. في هذه التجربة، فإننا سوف ك = 3، وتطبيق كتلة 4D في نهاية res4 I3D-S ResNet18. كما هو مبين في الجدول 2C، 3 3 3 3 نواة أقصى قدر من الأداء يمكن V4D. ومع ذلك، من خلال النظر في المفاضلة بين المعلمات نموذج والأداء في التجارب التالية، استخدمنا 3 3 1 1 النواة.
مواقف 4D وعدد من الكتل. قمنا بتقييم الآثار المترتبة على الموقف وعدد من الكتل V4D 4D باستخدام كتل 3 3 1 14D على res3، res4 أو res5 إلى V4D الأداء. كما هو مبين في الجدول 2D، أو عن طريق تطبيق res3 res4 يمكن الحصول على 4D مع ارتفاع كتلة دقة.
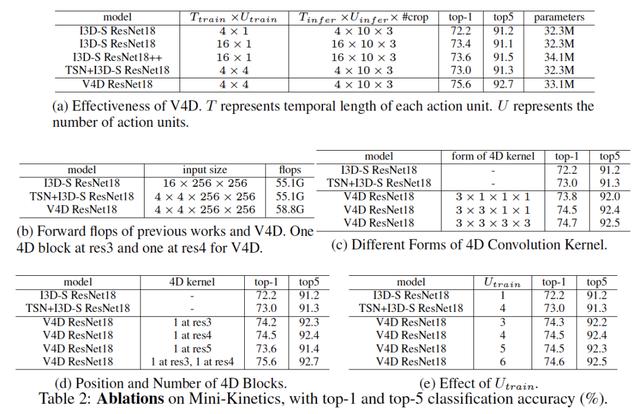
عدد وحدات تشغيل مختلفة. قمنا بتدريب V4D من خلال استخدام عدد مختلف من وحدات العمل، وذلك باستخدام قيم المعلمات مختلفة U_train. يتم إدخال هذه التجربة 3 3 1 14D كتلة res4 ResNet18 النهاية. كما هو مبين في الجدول رقم 2E، U_train تأثير لا كبير على الأداء، مما يشير إلى: (1) V4D هو نموذج التعلم ميزة مستوى الفيديو، وعدد من وحدات لديها متانة على المدى القصير؛ (2) عدد وافر من مراحل العملية عموما لا تحتوي على وبالتالي زيادة مساعدة مجانية. وبالإضافة إلى ذلك، فإن الزيادة في عدد الوحدات وسائل العمل التي يتم زيادة البعد الرابع، الأمر الذي يتطلب أكبر نواة 4D الزمكان تمثيل تطور التغطية.
مقارنة مع أحدث التقنيات. ونحن سوف V4D لدينا مقارنة مع أحدث أساليب السابقة. في res3 وres4، 4D المتبقية كتلة في كل مرة وحدة نمطية 3D. على الرغم من أن يتم استخدام إطار خلال التدريب وخلص إلى أن أقل مما لدينا V4D ResNet50 تقريرا عن نتائج كل إشارة لديها دقة أعلى من حتى مع وجود 5 الميثاق المعمم غير محلي كتلة 3D ResNet101 أعلى من ذلك. وبالإضافة إلى ذلك، يمكن لV4D ResNet18 تحقيق دقة أعلى من 3D ResNet50، ومن ثم مواصلة اثبات فعالية هيكل V4D لدينا.

4.3 حركية التجارب
ندرك كذلك الإشارة إلى نطاق واسع فيديو حركية-400 التجارب التي أجريت لتقييم قدرة V4D. وعلى سبيل المقارنة عادلة، كنا بمثابة العمود الفقري للV4D ResNet50. تدريب استراتيجية أخذ العينات والمنطق في القسم السابق إلا أن العملية كل خلية لديها الآن ثمانية بدلا من أربعة. ويرجع ذلك إلى تدريب الموارد محدودة، نختار نموذج تدريبي متعدد المراحل. نحن أول ثمانية التدريب المدخلات 3D ResNet50 العمود الفقري. ثم أننا تحميل المعلمات 3D ResNet50 إلى V4D ResNet50 بينما يتم تجميد جميع المعلمات 4D من الصفر. ثم 8 4 إطارات المدخلات V4D ResNet50 صقل. وأخيرا، فإننا الأمثل 4D جميع الكتل، وغسلها مع 8 4 إطارات تدريب V4D. كما هو مبين في الجدول رقم 4، حقق لدينا V4D النتائج التنافسية على حركية-400 معيار.
4.4 التجارب في شيء، شيء-V1
مقارنة مع ميني حركية وحركية، شيء، شيء على غرار إلى حد كبير على المعلومات في الوقت والحركة. نظافة الخلفية من حركية، ولكن فئة العمل الرياضي هو أكثر تعقيدا بكثير. شيء، شيء يحتوي على كل فيديو حركة مستمرة واحدة، مع بداية واضحة ونهاية في البعد الزمني.
النتائج. مقارنة مع الأعمال السابقة، كما هو مبين في الجدول رقم 4.4، وحصلنا على نتائج V4D قادرة على المنافسة في شيء، شيء-V1. نحن نستخدم تدريب ما قبل التجارب V4D ResNet50 حركية.

في الترتيب الزمني. عن طريق عكس ذلك الوقت، انخفضت دقة نموذج 3D بشكل كبير، مشيرا إلى أن 3D CNN أن نتعلم الترتيب الزمني قوي جدا. لV4D لدينا، هناك مستويين من الترتيب الزمني، من اجل قصيرة المدى وطويلة المدى. كما هو مبين في الجدول رقم 6، وتسلسل العملية من كل إطار، أو عن طريق عكس وحدة العملية في الخلية مقلوب، أعلى 1 انخفاض كبير في الدقة، فمن الممكن أن لدينا V4D طويلة وقصيرة القبض على التسلسل الزمني.

5 الاستنتاجات
قدمنا مستوى جديد من الفيديو 4D التفاف الشبكة العصبية، وهي V4D، لدراسة تطور الزمني لمسافات طويلة التمثيل الزماني والمكاني قوي، وميزة 3D احتفظت اتصالات المتبقية. وبالإضافة إلى ذلك، قدمنا أيضا أساليب التدريب والاستدلال V4D، نفذت تجارب على مؤشر ثلاثة الاعتراف الفيديو الذي V4D حصول على نتيجة جيدة.

التصور للنتيجة، أول السلوك فيديو RGB، سلوك الثانية TSN + I3D-S، وV4D السلوك الثالث
AI تقنية مراجعة سلسلة لايف
1، ACL 2020 - تفسير فودان سلسلة جامعة
يعيش موضوع: أحجام مختلفة من نظام تلخيص نص قابل للإزالة
رئيس مجلس النواب: وانغ Danqing، تشونغ مينغ
تشغيل الرابط: http: //mooc.yanxishe.com/open/course/804 (مدة تشغيل: في الساعة 22:00 يوم 26 ابريل)
يعيش الموضوع: مجموعة القواميس الصينية الاعتراف كيان اسمه [ACL 2020 - تفسير سلسلة فودان (ب)]
رئيس مجلس النواب: إذا تيان ما، لي هيو الذكور
يعيش الوقت: 26 أبريل (ليلة الأحد) 20:00 كله.
يعيش موضوع: ACL 2020 | التبعية نموذج إعراب ضد تحليل متانة عينة بناء
[ACL 2020 - سلسلة تفسير جامعة فودان (ج)]
رئيس مجلس النواب: تسنغ التشيكية الهواء
يعيش الوقت: 27 أبريل (ليلة الاثنين) 20:00 كله.
2، ICLR 2020 سلسلة لايف
موضوع الحية: ICLR 2020 شو شبكة العمل الدلالة: النظر في الآثار من إجراءات في نظام متعدد الوكلاء
رئيس مجلس النواب: وانغ وي شون
رابط القراءة: HTTP: //mooc.yanxishe.com/open/course/793
يعيش موضوع: ICLR 2020 شو الاستراتيجيات والتصحيح الذاتي قيمة ظيفة البيانات التعلم عن طريق خبراء من العينة سلبية
شاشة المطر لوه: رئيس
رابط القراءة: HTTP: //mooc.yanxishe.com/open/course/802
يعيش موضوع: ICLR 2020 شو دالة متعددة التعريف الخطية وظيفة تفعيل خسائر الشبكة العصبية شكل منحني
رئيس مجلس النواب: وفنغ شيانغ
رابط القراءة: HTTP: //mooc.yanxishe.com/open/course/801
كيفية الانضمام؟
