وقبل أيام قليلة، أعلن فريق تشن تيانتشى TVM، على قالت المدونات الصغيرة "، أصدرنا اليوم TVM، ومعا يشكلون دراسة متعمقة NNVM إلى إكمال مجموعة متنوعة من سلسلة أداة الأجهزة الأمثل لدعم الهاتف المحمول، وكودا، opencl، والمعادن، وجافا سكريبت و أخرى مختلفة في نهاية العام. مرحبا بكم في نظرية التعلم مترجم عميقة، والحوسبة عالية الأداء، تسارع الطلاب الراغبين للانضمام معا لتعزيز الرائدة في مشاريع مفتوحة المصدر dmlc المجتمع ".
وفقا لشبكة لى فنغ AI تكنولوجي ريفيو ومن المعلوم أن معظم النظم القائمة هي الأمثل لنطاق ضيق من GPU على مستوى الخادم، والحاجة إلى نشر الكثير من العمل على، بما في ذلك الهواتف النقالة، أجهزة IOT والمعجلات مخصصة. وTVM هو كومة التعلم نشر عبء الأجهزة نهاية عمق IR (تمثيل وسيط). وبعبارة أخرى، فإن هذا النوع من الحلول يمكن توزيعها على نموذج التعلم العميق على مجموعة متنوعة من الأجهزة، لتحقيق حد لضبط النهاية.
ذلك هو وجود ثلاث خصائص:
-
إلى وحدة المعالجة المركزية الأمثل، GPU وغيرها من الأجهزة الحاسوبية المتخصصة في عمق منتظم مهام التعلم.
-
FIG حساب يمكن تحويلها تلقائيا، بحيث يتم التقليل من استخدام الذاكرة، لتحسين تخطيط البيانات، ووضع الحساب لالانصهار.
-
تم تجميعها من الواجهة الأمامية القائمة لتوفير نهاية الأجهزة المعدنية العارية، والمتصفح جافاسكريبتس القابل للتنفيذ.
وقد علمت لى فنغ شبكة AI تكنولوجيا مراجعة، TVM بلوق هو يصف الورقة الأولى:
"مع مساعدة من TVM والمطورين تحتاج فقط كمية صغيرة من العمل الإضافي، يمكنك تشغيل بسهولة على الجانب الهاتف المحمول، والأجهزة المدمجة وحتى على عمق المهام تعلم .TVM متصفح يوفر أيضا دراسة موحدة عمق وحجم العمل عبر منصات الأجهزة متعددة الإطار الأمثل، بما في ذلك الاعتماد على الحوسبة الجديدة معجل مخصص البدائية ".
واليوم، أصدرت تشن تيانتشى دينامية جديدة على المدونات الصغيرة إلى البرنامج التعليمي المقبل عرض توكسون هو جين وي التركيز على تعزيز التعلم العميق الأمثل المرجع من TVM.
"في العمق المرجع التعلم الأمثل هو مهم جدا ولكن من الصعب السؤال. من كتب توكسون المستقبل هو جين وي تعليمي يصف كيفية تحقيق الاستخدام الأمثل للTVM دراسة متعمقة من المرجع الجرافيك، من القائمة فريق العمل من خلال الحصول على بضع عشرات من خطوط رمز لتحقيق ثلاثة وعشرين الثعبان أضعاف الزيادة ".
كما تحديث هذه المقالة في وقت واحد على TVM بلوق، لى فنغ شبكة AI تقنية مراجعة أول مرة للقيام تغطية وإعداد التقارير.
هو جين وى، ماجستير في الهندسة الإلكترونية من جامعة بكين للملاحة الجوية والفضائية، حاليا فجوة العام، والآن توكسون المستقبل ممارسة مجموعة HPC. المقال بعنوان "تحسين ديب التعلم GPU مشغلي مع TVM: A Depthwise الإلتواء مثال" (لDepthwise الإلتواء، على سبيل المثال، لتحقيق الاستخدام الأمثل للTVM التعلم العميق مشغل GPU)
كفاءة المشغل العميق التعلم نظام التعلم هو عمق الأساسية. هذه الشركات عادة ما يصعب الأمثل، يحتاج خبراء HPC لدفع الكثير من الجهد. TVM كغاية إلى موتر IR / DSL المكدس، يمكن أن تجعل من العملية برمتها أسهل.
وتنص هذه المادة على إشارة جيدة، وكيفية المطورين تعليم لكتابة عالية الأداء GPU الأساسية بمساعدة مشغلي TVM. ويستخدم فريق Depthwise الإلتواء (أي topi.nn.depthwise_conv2d_nchw) كمثال على ذلك، ويوضح كيف يمكنك تحسين بالفعل يدويا الأمثل TensorFlow نواة CUDA.
وصف المقال باستخدام إصدار TVM النهائي 2-4 مرات أسرع من فريق العمل 1.2 تحت الأحمال تشغيل مختلفة تحسين النواة، والانصهار مشغل ثلاث مرات أسرع -7 مرات. وفيما يلي نتائج الاختبار تحت GTX1080، مرشح حجم = ، خطوة = ، الحشو = 'نفس':

Depthwise الإلتواء هو الفكرة الأساسية لبناء نموذج يمكن أن تقلل بشكل فعال من التعقيد الحسابي لعمق الشبكات العصبية، بما في ذلك Xception جوجل وMobileNet تنتمي Depthwise الإلتواء.

في بيئة TVM، تشغيل التعليمات البرمجية Depthwise الإلتواء على النحو التالي:
# الحشو stagePaddedInput = tvm.compute (
(الدفعة، in_channel، height_after_pad، width_after_pad)،
امدا ب، ج، ط، ي: tvm.select (
tvm.all (ط > = Pad_top، ط - pad_top = pad_left، ي - الإدخال pad_left ، Tvm.const (0.0))،
اسم = "PaddedInput") # depthconv stagedi = tvm.reduce_axis ((0، filter_height)، اسم = 'دي') دي جي = tvm.reduce_axis ((0، filter_width)، اسم = 'دي جي') الناتج = tvm.compute (
(الدفعة، out_channel، out_height، out_width)،
امدا ب، ج، ط، ي: tvm.sum (
PaddedInput * تصفية ،
محور = )،
اسم = 'DepthwiseConv2d')
المرشد العام GPU الأمثل
ذكر هو جين تاو وي ثلاث قضايا رئيسية عند تحسين كود CUDA عادة وتجدر الإشارة في المادة، وهذا هو، إعادة استخدام البيانات (إعادة استخدام البيانات)، الذاكرة المشتركة (الذاكرة المشتركة) وانتهاك وصول (صراعات البنك).
في بنية الحوسبة الحديثة، ويتم احتساب التكلفة من تحميل البيانات من الذاكرة هو أعلى بكثير من النقطة العائمة واحدة. وفقا لذلك، ونحن نريد ليتم تحميلها إلى تسجيل أو ذاكرة التخزين المؤقت يمكن استخدامها مرة أخرى في إدخال البيانات.
هناك نوعان من النماذج في التفاف depthwise إعادة استخدام البيانات: مرشحات مدخلات إعادة استخدامها وإعادة استخدامها، والشرائح السابقة على قناة المدخلات وبحساب عدد وافر من الأوقات، والذي يحدث عندما يكون البلاط، وعلى سبيل المثال ل3X3 depthwise الإلتواء:

دون البلاط، كل موضوع وبحساب ناتج الحمل 3X3 العناصر إدخال البيانات. ما مجموعه 16 المواضيع 9x16 الأحمال.

البلاط، كل موضوع يحسب 2X24X4 مخرجات العناصر إدخال البيانات والأحمال. ما مجموعه 4 المواضيع 16x4 الأحمال.
والذاكرة المشتركة انتهاك وصول
عازلة الذاكرة المشتركة يمكن أن ينظر إليه GPU، وأسرع على الورقة. وجرت العادة على تحميل البيانات من الذاكرة العالمية إلى الذاكرة المشتركة، وقراءة كل المواضيع في بيانات كتلة من الذاكرة المشتركة.

من أجل تجنب حدوث انتهاك وصول، وهو موضوع المستمر من الوصول المستمر لأفضل عنوان الذاكرة كما هو مبين (كل لون يمثل بنك الذاكرة المشتركة):
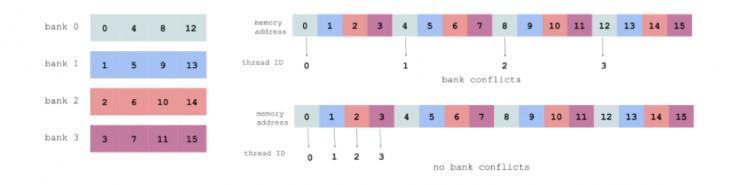
للحصول على تفاصيل تشير https://devblogs.nvidia.com/parallelforall/using-shared-memory-cuda-cc/
عملية التحسين محددة
الحوسبة إدخال خط التعبئة لإنقاذ تخصيص الذاكرة
وذكر الحشو صراحة كمرحلة منفصلة. عن طريق حساب تخصيص الذاكرة المضمنة في التكرار تجنب:
الصورة = tvm.create_schedule (Output.op) ق .compute_inline
مرور كتلة كبيرة إلى أصغر
نهج بسيط هو CUDA تجهيز مبنى قناة المدخلات والمرشحات المقابلة، لحساب الذاكرة المشتركة بعد التحميل:
IS = s.cache_read (PaddedInput، "المشتركة"، )
FS = s.cache_read (تصفية، "المشتركة"، )
block_y = tvm.thread_axis ( "blockIdx.y")
block_x = tvm.thread_axis ( "blockIdx.x")
# ربط البعد الدفعة (N في NCHW) مع block_y
الصورة .bind (Output.op.axis ، block_y)
# ربط البعد من قناة (C في NCHW) مع block_x
الصورة .bind (Output.op.axis ، block_x)
الشكل التالي يبين نتائج الاختبار، فإن متوسط تكلفة وقت تشغيل مرات GTX 10801000 ومقارنة في tensorflow وdepthwise_conv2d.
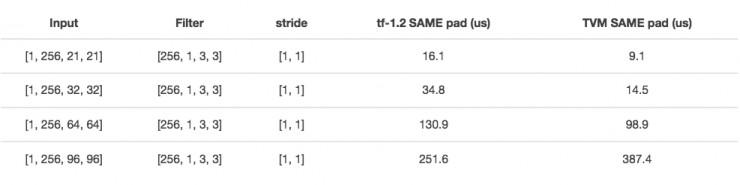
إذا كانت القناة هي 21 21 أو 32 32 الحجم، وأداء جيد، ولكن إذا كان 64 64، ثم أداء سيتم انخفض إلى حد كبير. إذا قمت بإجراء بعض التغييرات، ثم تأثير سيزيد كثيرا:

عدد المواضيع المعلمة تعديل
كاتب المحرز في كتلة CUDA 32 32، على النحو التالي:

كيف num_thread_y وnum_thread_x هذه المعلمتين تعديلها للحصول على الحل الأمثل؟ في تصفية = وخطوة = أدناه:

من خلال الاختبار، وحصل الفريق على النتائج التالية:
-
على نطاق واسع إعادة استخدام البيانات البلاط هو جيد، ولكن لا يؤدي إلى قراءة الذاكرة المحلية.
-
آثار مختلفة num_thread_y والوصول num_thread_x للصراع.
-
وnum_thread_x num_thread_y أفضل مزيج من الوصول المشترك الذاكرة المطلوبة لتحقيق (منطقة تخزين الصراعات تجنب) كفاءة وإعادة استخدام البيانات، وميزان الذاكرة المحلية قراءة.
قبل بحث شامل، وTVM يمكننا num_thread_y وnum_thread_x مرت كوسائط للجدول الزمني وظيفة، ومحاولة كل مزيج ممكن للعثور على مزيج الأمثل.

Vthread (موضوع الظاهري) وStrided أنماط
في TVM، يمكن Vthread الدعم الفعال أنماط Strided.

تصفية القضية = ، خطوة = ، blocking_h = 32، blocking_w = 32، وكانت النتائج على النحو التالي:

أسرع مما كان عليه الحال حالة 12، منذ قضية 2 num_thread_x = 8 و num_vthread_x = 4 حالة، لضمان المواضيع مستمرة الوصول عناوين الذاكرة متتالية، من أجل الوصول إلى الصراعات تجنب، كما هو مبين (كل لون يمثل موضوع عبء العمل):

أذكر مرة أخرى وعلى النقيض من Tensorflow:

مشغلي الانصهار
مشغل الانصهار هو وسيلة نموذجية لتحسين شبكة التعلم العمق، في TVM في النظر في النموذج الأصلي depthwise_conv2d + scale_shift + relu، يمكن تعديلها قليلا على النحو التالي:

ولدت IR على النحو التالي:
/ * الإدخال = ، تصفية = ، خطوة = ، الحشو = 'SAME' * / إنتاج Relu {
// ATTR thread_extent = 1 // ATTR storage_scope = "المحلية" تخصيص DepthwiseConv2d
// ATTR thread_extent = 1 // ATTR thread_extent = 8 // ATTR thread_extent = 8 المنتجات DepthwiseConv2d {
ل(ط، 0، 4) {
ل(ي، 0، 4) {
DepthwiseConv2d = 0.000000f
ل(دي، 0، 3) {
ل(دي جي، 0، 3) {
DepthwiseConv2d = (DepthwiseConv2d + (tvm_if_then_else (((((((1 - دي) - ط)}
}
}
}
}
ل(i2.inner.inner.inner، 0، 4) {
ل(i3.inner.inner.inner، 0، 4) {
Relu = ماكس (((DepthwiseConv2d * مقياس ) + التحول )، 0.000000f)
}
}}
يمكنك ان ترى كل موضوع قبل أن يتم كتابة النتائج depthwise_conv2d الذاكرة العمومية، يحسب scale_shift وrelu. الانصهار مع مشغل واحد depthwise_conv2d بأسرع. ما يلي هو = الإدخال ، تصفية = ، خطوة = ، نتائج الحشو = 'SAME "هي:
-
فريق العمل 1.2 depthwise_conv2d: 251.6 لنا
-
فريق العمل 1.2 depthwise_conv2d + scale_shift + relu (منفصل): 419.9 لنا
-
TVM depthwise_conv2d: 90.9 لنا
-
TVM depthwise_conv2d + scale_shift + relu (الانصهار): 91.5 لنا
رمز أكثر الأمثل يمكن الرجوع إلى الروابط التالية:
تعلن: https://github.com/dmlc/tvm/blob/master/topi/python/topi/nn/convolution.py
الجدول الزمني: https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/depthwise_conv2d.py
اختبار: https://github.com/dmlc/tvm/blob/master/topi/recipe/conv/depthwise_conv2d_test.py